 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Classification via Transformer Neural Networks: Case Study of an Educational Domain
Paper and Code

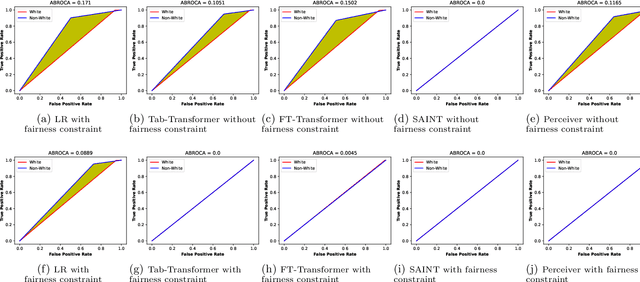
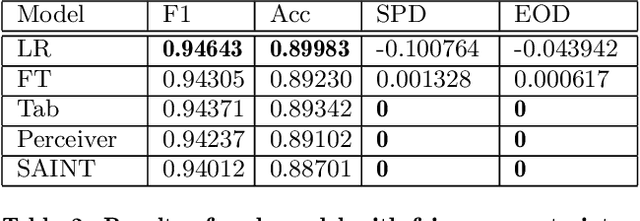
Educational technologies nowadays increasingly use data and Machine Learning (ML) models. This gives the students, instructors, and administrators support and insights for the optimum policy. However, it is well acknowledged that ML models are subject to bias, which raises concern about the fairness, bias, and discrimination of using these automated ML algorithms in education and its unintended and unforeseen negative consequences. The contribution of bias during the decision-making comes from datasets used for training ML models and the model architecture. This paper presents a preliminary investigation of fairness constraint in transformer neural networks on Law School and Student-Mathematics datasets. The used transformer models transform these raw datasets into a richer representation space of natural language processing (NLP) while solving fairness classification. We have employed fairness metrics for evaluation and check the trade-off between fairness and accuracy. We have reported the various metrics of F1, SPD, EOD, and accuracy for different architectures from the transformer model class.