 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFail-Safe Generative Adversarial Imitation Learning
Paper and Code
Mar 03, 2022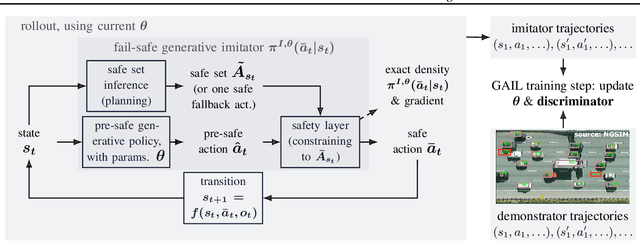


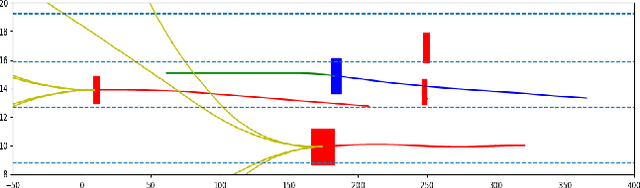
For flexible yet safe imitation learning (IL), we propose a modular approach that uses a generative imitator policy with a safety layer, has an overall explicit density/gradient, can therefore be end-to-end trained using generative adversarial IL (GAIL), and comes with theoretical worst-case safety/robustness guarantees. The safety layer's exact density comes from using a countable non-injective gluing of piecewise differentiable injections and the change-of-variables formula. The safe set (into which the safety layer maps) is inferred by sampling actions and their potential future fail-safe fallback continuations, together with Lipschitz continuity and convexity arguments. We also provide theoretical bounds showing the advantage of using the safety layer already during training (imitation error linear in the horizon) compared to only using it at test time (quadratic error). In an experiment on challenging real-world driver interaction data, we empirically demonstrate tractability, safety and imitation performance of our approach.