 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitate the Parametric Dimension Reduction by Gradient Clipping
Paper and Code
Sep 30, 2020
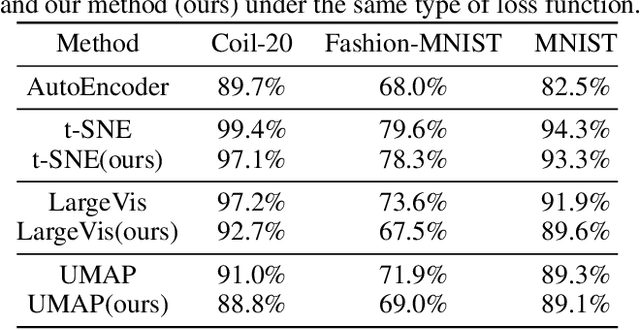
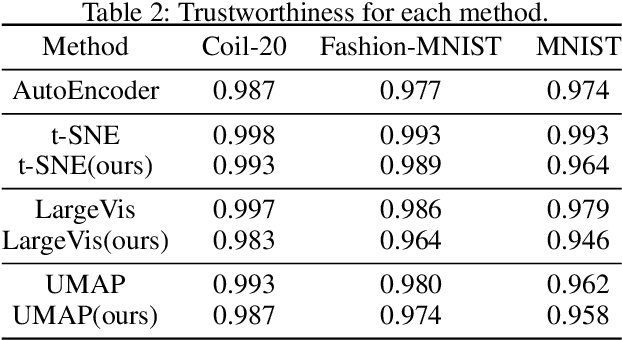
We extend a well-known dimension reduction method, t-distributed stochastic neighbor embedding (t-SNE), from non-parametric to parametric by training neural networks. The main advantage of a parametric technique is the generalization of handling new data, which is particularly beneficial for streaming data exploration. However, training a neural network to optimize the t-SNE objective function frequently fails. Previous methods overcome this problem by pre-training and then fine-tuning the network. We found that the training failure comes from the gradient exploding problem, which occurs when data points distant in high-dimensional space are projected to nearby embedding positions. Accordingly, we applied the gradient clipping method to solve the problem. Since the networks are trained by directly optimizing the t-SNE objective function, our method achieves an embedding quality that is compatible with the non-parametric t-SNE while enjoying the ability of generalization. Due to mini-batch network training, our parametric dimension reduction method is highly efficient. We further extended other non-parametric state-of-the-art approaches, such as LargeVis and UMAP, to the parametric versions. Experiment results demonstrate the feasibility of our method. Considering its practicability, we will soon release the codes for public use.