 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Keywords from Open-Ended Business Survey Questions
Paper and Code

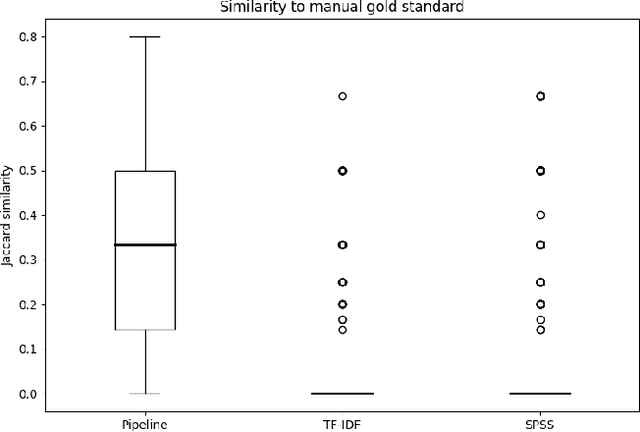


Open-ended survey data constitute an important basis in research as well as for making business decisions. Collecting and manually analysing free-text survey data is generally more costly than collecting and analysing survey data consisting of answers to multiple-choice questions. Yet free-text data allow for new content to be expressed beyond predefined categories and are a very valuable source of new insights into people's opinions. At the same time, surveys always make ontological assumptions about the nature of the entities that are researched, and this has vital ethical consequences. Human interpretations and opinions can only be properly ascertained in their richness using textual data sources; if these sources are analyzed appropriately, the essential linguistic nature of humans and social entities is safeguarded. Natural Language Processing (NLP) offers possibilities for meeting this ethical business challenge by automating the analysis of natural language and thus allowing for insightful investigations of human judgements. We present a computational pipeline for analysing large amounts of responses to open-ended questions in surveys and extract keywords that appropriately represent people's opinions. This pipeline addresses the need to perform such tasks outside the scope of both commercial software and bespoke analysis, exceeds the performance to state-of-the-art systems, and performs this task in a transparent way that allows for scrutinising and exposing potential biases in the analysis. Following the principle of Open Data Science, our code is open-source and generalizable to other datasets.