 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting and Analyzing Semantic Relatedness between Cities Using News Articles
Paper and Code
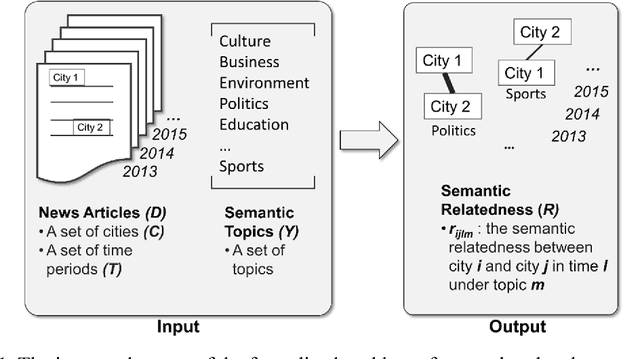

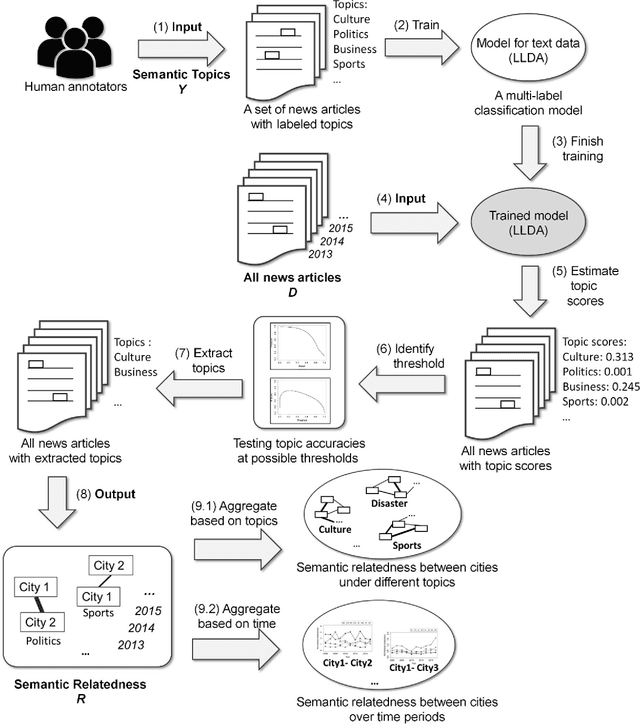

News articles capture a variety of topics about our society. They reflect not only the socioeconomic activities that happened in our physical world, but also some of the cultures, human interests, and public concerns that exist only in the perceptions of people. Cities are frequently mentioned in news articles, and two or more cities may co-occur in the same article. Such co-occurrence often suggests certain relatedness between the mentioned cities, and the relatedness may be under different topics depending on the contents of the news articles. We consider the relatedness under different topics as semantic relatedness. By reading news articles, one can grasp the general semantic relatedness between cities, yet, given hundreds of thousands of news articles, it is very difficult, if not impossible, for anyone to manually read them. This paper proposes a computational framework which can "read" a large number of news articles and extract the semantic relatedness between cities. This framework is based on a natural language processing model and employs a machine learning process to identify the main topics of news articles. We describe the overall structure of this framework and its individual modules, and then apply it to an experimental dataset with more than 500,000 news articles covering the top 100 U.S. cities spanning a 10-year period. We perform exploratory visualization of the extracted semantic relatedness under different topics and over multiple years. We also analyze the impact of geographic distance on semantic relatedness and find varied distance decay effects. The proposed framework can be used to support large-scale content analysis in city network research.