 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Environments To Measure Self-Reflection In Reinforcement Learning
Paper and Code
Oct 13, 2021
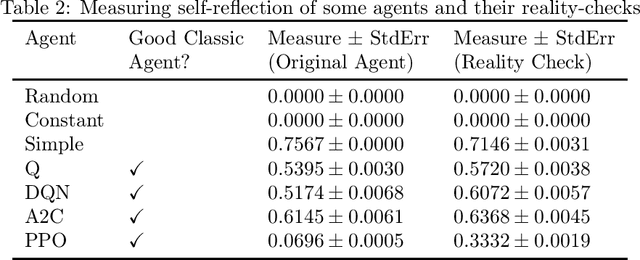
We consider an extended notion of reinforcement learning in which the environment can simulate the agent and base its outputs on the agent's hypothetical behavior. Since good performance usually requires paying attention to whatever things the environment's outputs are based on, we argue that for an agent to achieve on-average good performance across many such extended environments, it is necessary for the agent to self-reflect. Thus, an agent's self-reflection ability can be numerically estimated by running the agent through a battery of extended environments. We are simultaneously releasing an open-source library of extended environments to serve as proof-of-concept of this technique. As the library is first-of-kind, we have avoided the difficult problem of optimizing it. Instead we have chosen environments with interesting properties. Some seem paradoxical, some lead to interesting thought experiments, some are even suggestive of how self-reflection might have evolved in nature. We give examples and introduce a simple transformation which experimentally seems to increase self-reflection.