 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Deep-faked Videos by Anomalous Co-motion Pattern Detection
Paper and Code
Aug 11, 2020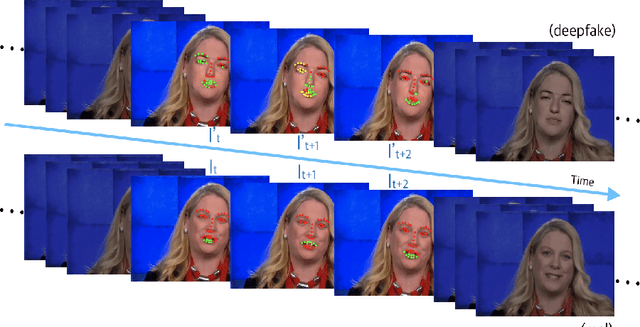



Recent deep learning based video synthesis approaches, in particular with applications that can forge identities such as "DeepFake", have raised great security concerns. Therefore, corresponding deep forensic methods are proposed to tackle this problem. However, existing methods are either based on unexplainable deep networks which greatly degrades the principal interpretability factor to media forensic, or rely on fragile image statistics such as noise pattern, which in real-world scenarios can be easily deteriorated by data compression. In this paper, we propose an fully-interpretable video forensic method that is designed specifically to expose deep-faked videos. To enhance generalizability on videos with various content, we model the temporal motion of multiple specific spatial locations in the videos to extract a robust and reliable representation, called Co-Motion Pattern. Such kind of conjoint pattern is mined across local motion features which is independent of the video contents so that the instance-wise variation can also be largely alleviated. More importantly, our proposed co-motion pattern possesses both superior interpretability and sufficient robustness against data compression for deep-faked videos. We conduct extensive experiments to empirically demonstrate the superiority and effectiveness of our approach under both classification and anomaly detection evaluation settings against the state-of-the-art deep forensic methods.