 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of Synthetic Data to Replace Real Data
Paper and Code
Aug 26, 2024


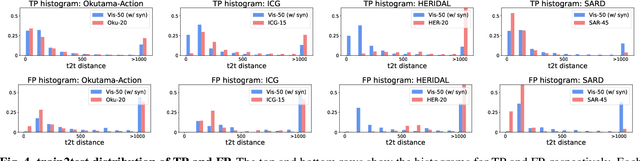
The potential of synthetic data to replace real data creates a huge demand for synthetic data in data-hungry AI. This potential is even greater when synthetic data is used for training along with a small number of real images from domains other than the test domain. We find that this potential varies depending on (i) the number of cross-domain real images and (ii) the test set on which the trained model is evaluated. We introduce two new metrics, the train2test distance and $\text{AP}_\text{t2t}$, to evaluate the ability of a cross-domain training set using synthetic data to represent the characteristics of test instances in relation to training performance. Using these metrics, we delve deeper into the factors that influence the potential of synthetic data and uncover some interesting dynamics about how synthetic data impacts training performance. We hope these discoveries will encourage more widespread use of synthetic data.