 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of Feature Density in Estimating Machine Learning Classifier Performance with Application to Cyberbullying Detection
Paper and Code
Jun 04, 2022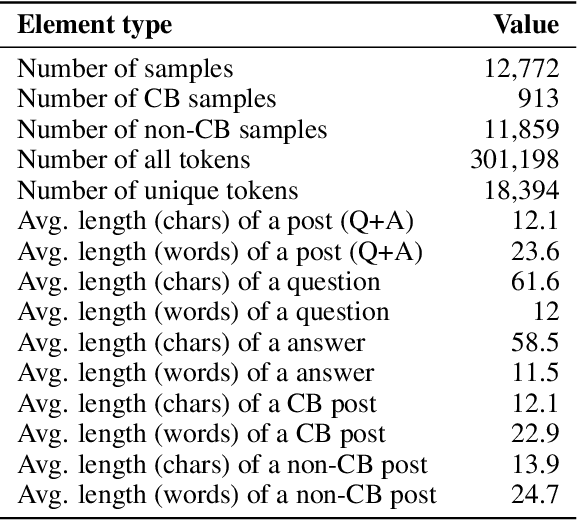
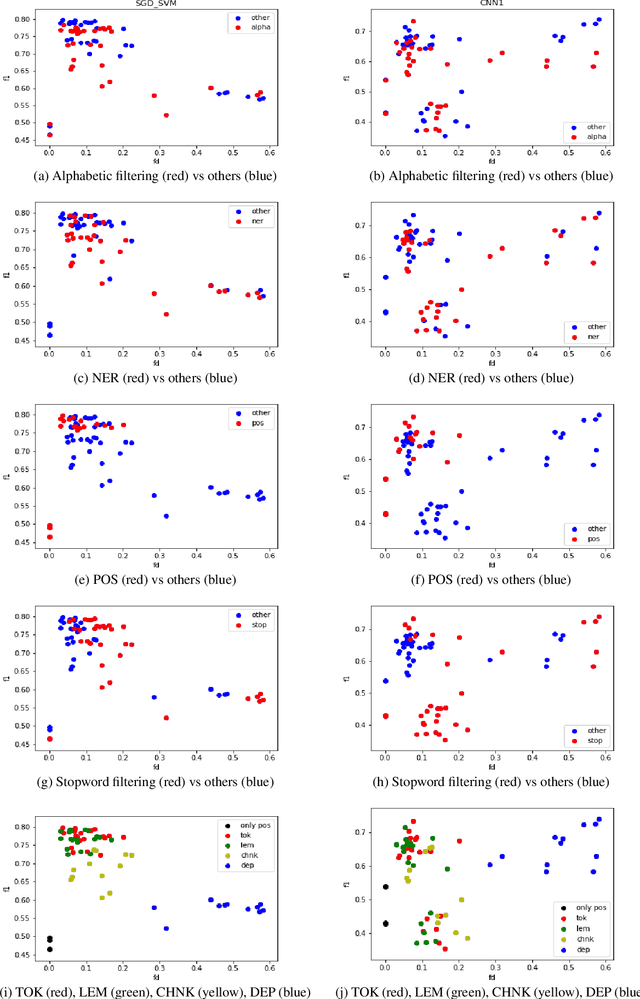

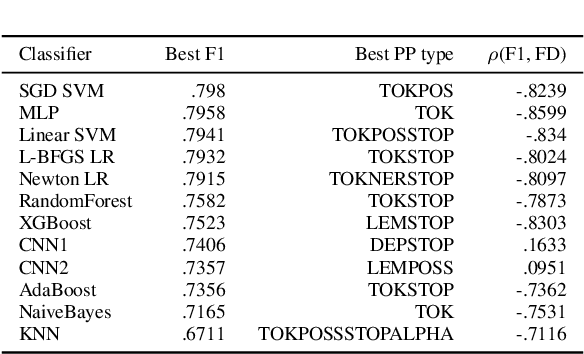
In this research. we analyze the potential of Feature Density (HD) as a way to comparatively estimate machine learning (ML) classifier performance prior to training. The goal of the study is to aid in solving the problem of resource-intensive training of ML models which is becoming a serious issue due to continuously increasing dataset sizes and the ever rising popularity of Deep Neural Networks (DNN). The issue of constantly increasing demands for more powerful computational resources is also affecting the environment, as training large-scale ML models are causing alarmingly-growing amounts of CO2, emissions. Our approach 1s to optimize the resource-intensive training of ML models for Natural Language Processing to reduce the number of required experiments iterations. We expand on previous attempts on improving classifier training efficiency with FD while also providing an insight to the effectiveness of various linguistically-backed feature preprocessing methods for dialog classification, specifically cyberbullying detection.