 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring The Contribution of Unlabeled Data in Financial Sentiment Analysis
Paper and Code
Aug 03, 2013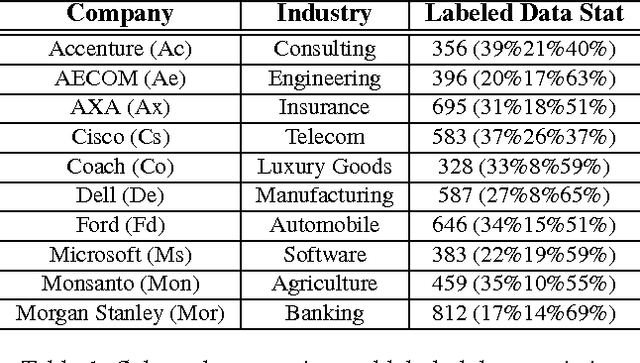
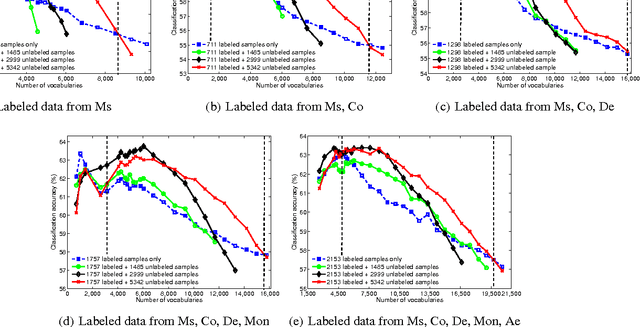
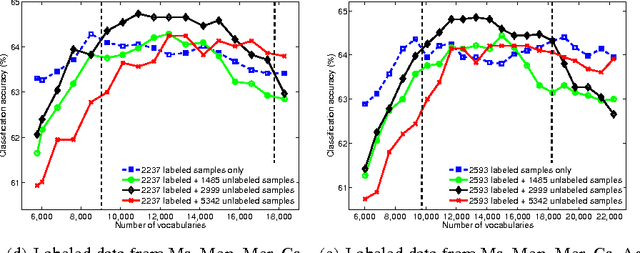
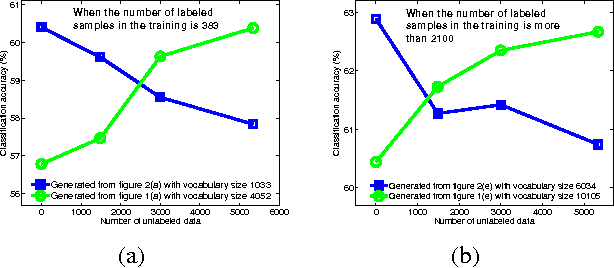
With the proliferation of its applications in various industries, sentiment analysis by using publicly available web data has become an active research area in text classification during these years. It is argued by researchers that semi-supervised learning is an effective approach to this problem since it is capable to mitigate the manual labeling effort which is usually expensive and time-consuming. However, there was a long-term debate on the effectiveness of unlabeled data in text classification. This was partially caused by the fact that many assumptions in theoretic analysis often do not hold in practice. We argue that this problem may be further understood by adding an additional dimension in the experiment. This allows us to address this problem in the perspective of bias and variance in a broader view. We show that the well-known performance degradation issue caused by unlabeled data can be reproduced as a subset of the whole scenario. We argue that if the bias-variance trade-off is to be better balanced by a more effective feature selection method unlabeled data is very likely to boost the classification performance. We then propose a feature selection framework in which labeled and unlabeled training samples are both considered. We discuss its potential in achieving such a balance. Besides, the application in financial sentiment analysis is chosen because it not only exemplifies an important application, the data possesses better illustrative power as well. The implications of this study in text classification and financial sentiment analysis are both discussed.