 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Heterogeneous Information Networks via Pre-Training
Paper and Code
Jul 07, 2020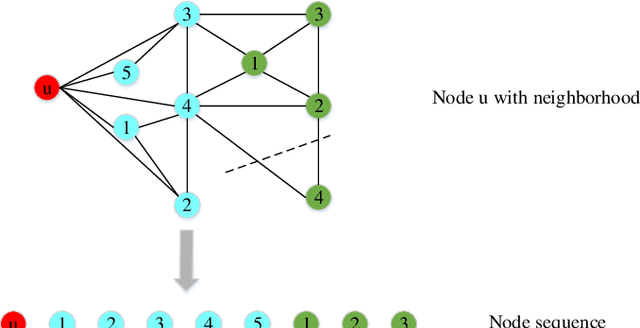
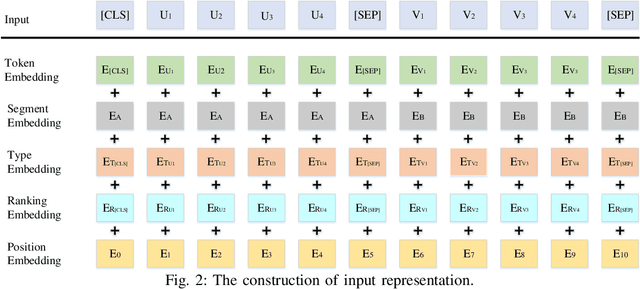
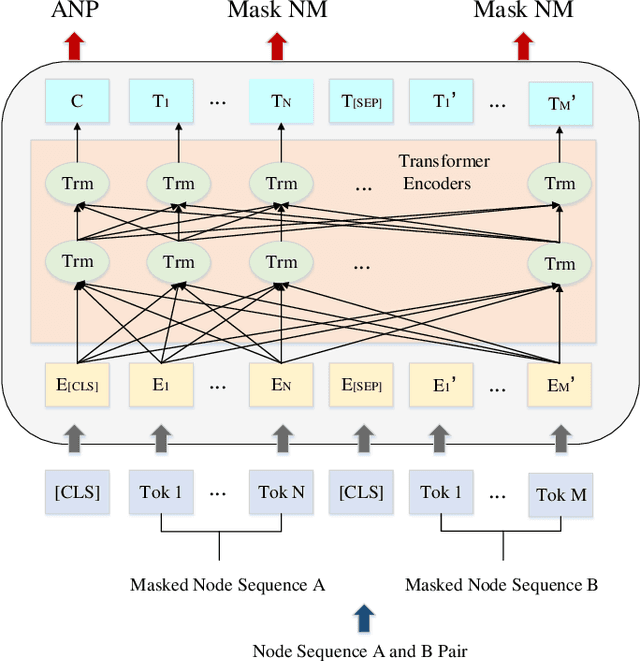
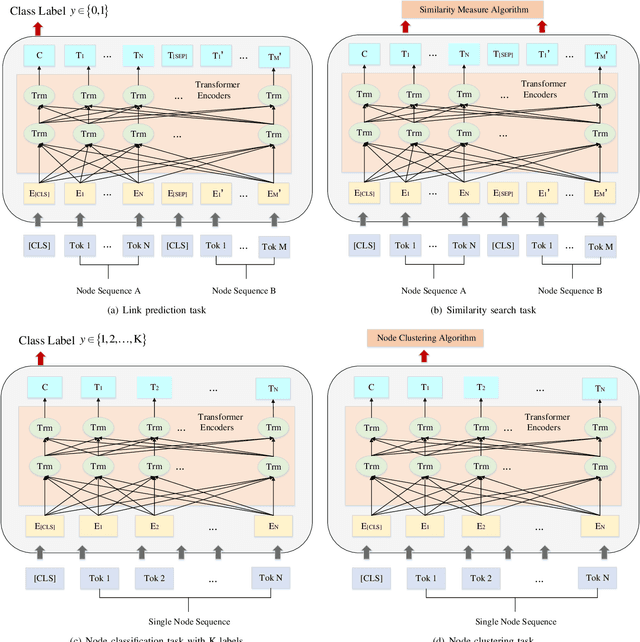
To explore heterogeneous information networks (HINs), network representation learning (NRL) is proposed, which represents a network in a low-dimension space. Recently, graph neural networks (GNNs) have drawn a lot of attention which are very expressive for mining a HIN, while they suffer from low efficiency issue. In this paper, we propose a pre-training and fine-tuning framework PF-HIN to capture the features of a HIN. Unlike traditional GNNs that have to train the whole model for each downstream task, PF-HIN only needs to fine-tune the model using the pre-trained parameters and minimal extra task-specific parameters, thus improving the model efficiency and effectiveness. Specifically, in pre-training phase, we first use a ranking-based BFS strategy to form the input node sequence. Then inspired by BERT, we adopt deep bi-directional transformer encoders to train the model, which is a variant of GNN aggregator that is more powerful than traditional deep neural networks like CNN and LSTM. The model is pre-trained based on two tasks, i.e., masked node modeling (MNM) and adjacent node prediction (ANP). Additionally, we leverage factorized embedding parameterization and cross-layer parameter sharing to reduce the parameters. In fine-tuning stage, we choose four benchmark downstream tasks, i.e., link prediction, similarity search, node classification and node clustering. We use node sequence pairs as input for link prediction and similarity search, and a single node sequence as input for node classification and clustering. The experimental results of the above tasks on four real-world datasets verify the advancement of PF-HIN, as it outperforms state-of-the-art alternatives consistently and significantly.