Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Hate Speech Detection in Multimodal Publications
Paper and Code

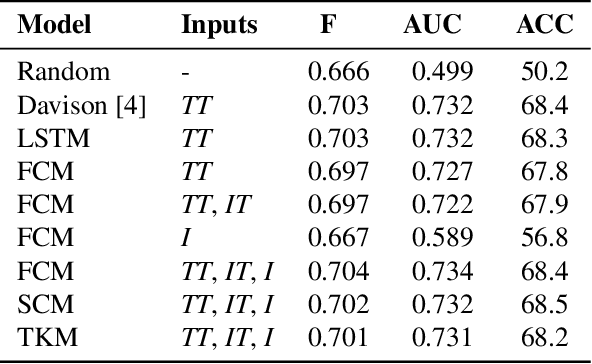
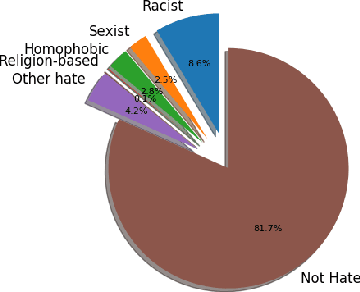

In this work we target the problem of hate speech detection in multimodal publications formed by a text and an image. We gather and annotate a large scale dataset from Twitter, MMHS150K, and propose different models that jointly analyze textual and visual information for hate speech detection, comparing them with unimodal detection. We provide quantitative and qualitative results and analyze the challenges of the proposed task. We find that, even though images are useful for the hate speech detection task, current multimodal models cannot outperform models analyzing only text. We discuss why and open the field and the dataset for further research.
View paper on