Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring End-to-End Techniques for Low-Resource Speech Recognition
Paper and Code
Jul 02, 2018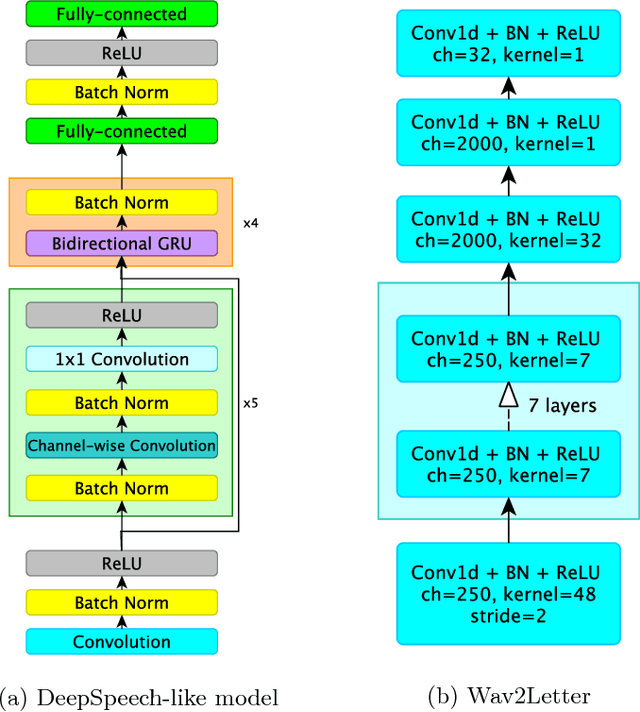
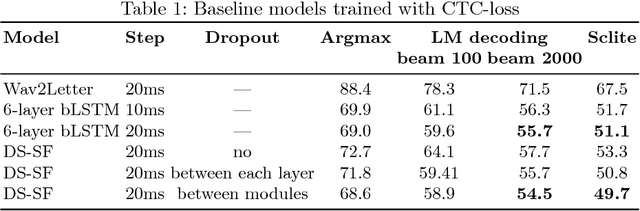
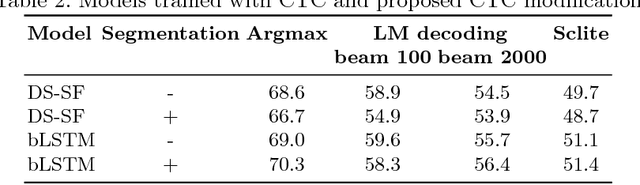
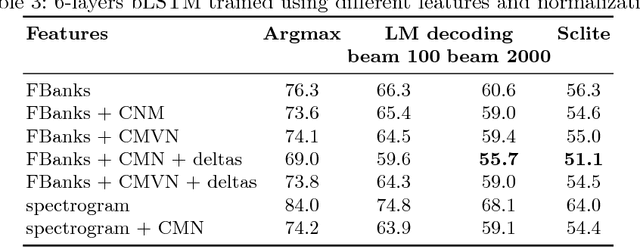
In this work we present simple grapheme-based system for low-resource speech recognition using Babel data for Turkish spontaneous speech (80 hours). We have investigated different neural network architectures performance, including fully-convolutional, recurrent and ResNet with GRU. Different features and normalization techniques are compared as well. We also proposed CTC-loss modification using segmentation during training, which leads to improvement while decoding with small beam size. Our best model achieved word error rate of 45.8%, which is the best reported result for end-to-end systems using in-domain data for this task, according to our knowledge.
* Accepted for Specom 2018, 20th International Conference on Speech and
Computer
View paper on