 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Bias in GAN-based Data Augmentation for Small Samples
Paper and Code
May 21, 2019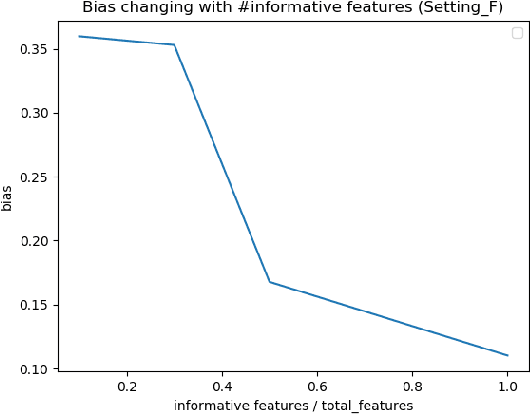



For machine learning task, lacking sufficient samples mean the trained model has low confidence to approach the ground truth function. Until recently, after the generative adversarial networks (GAN) had been proposed, we see the hope of small samples data augmentation (DA) with realistic fake data, and many works validated the viability of GAN-based DA. Although most of the works pointed out higher accuracy can be achieved using GAN-based DA, some researchers stressed that the fake data generated from GAN has inherent bias, and in this paper, we explored when the bias is so low that it cannot hurt the performance, we set experiments to depict the bias in different GAN-based DA setting, and from the results, we design a pipeline to inspect specific dataset is efficiently-augmentable with GAN-based DA or not. And finally, depending on our trial to reduce the bias, we proposed some advice to mitigate bias in GAN-based DA application.