 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Locality in Searching the Web
Paper and Code
Oct 19, 2012
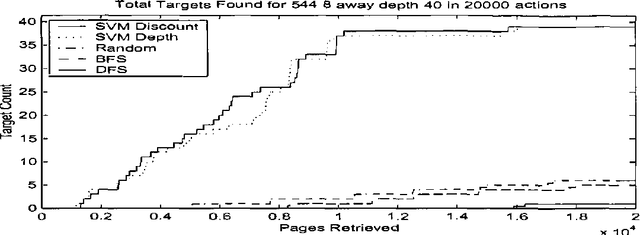
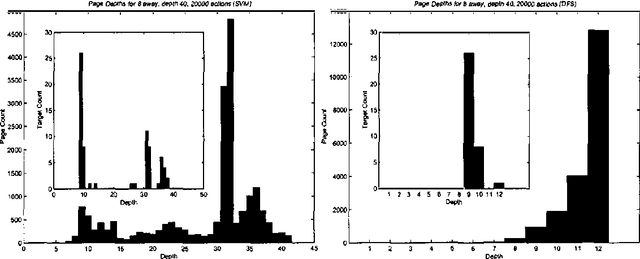

Published experiments on spidering the Web suggest that, given training data in the form of a (relatively small) subgraph of the Web containing a subset of a selected class of target pages, it is possible to conduct a directed search and find additional target pages significantly faster (with fewer page retrievals) than by performing a blind or uninformed random or systematic search, e.g., breadth-first search. If true, this claim motivates a number of practical applications. Unfortunately, these experiments were carried out in specialized domains or under conditions that are difficult to replicate. We present and apply an experimental framework designed to reexamine and resolve the basic claims of the earlier work, so that the supporting experiments can be replicated and built upon. We provide high-performance tools for building experimental spiders, make use of the ground truth and static nature of the WT10g TREC Web corpus, and rely on simple well understand machine learning techniques to conduct our experiments. In this paper, we describe the basic framework, motivate the experimental design, and report on our findings supporting and qualifying the conclusions of the earlier research.