 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Local and Global Features in Transformer-based Extreme Multi-label Text Classification
Paper and Code
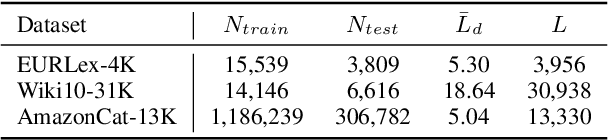
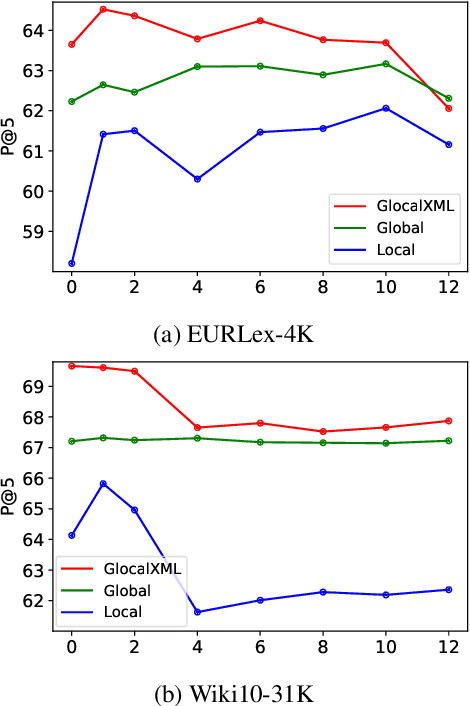
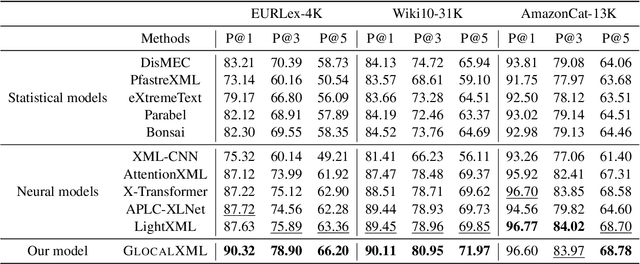
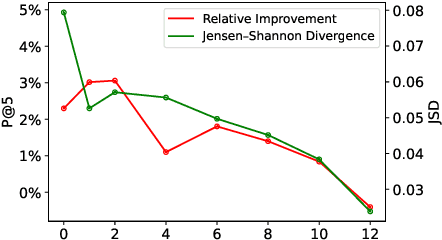
Extreme multi-label text classification (XMTC) is the task of tagging each document with the relevant labels from a very large space of predefined categories. Recently, large pre-trained Transformer models have made significant performance improvements in XMTC, which typically use the embedding of the special CLS token to represent the entire document semantics as a global feature vector, and match it against candidate labels. However, we argue that such a global feature vector may not be sufficient to represent different granularity levels of semantics in the document, and that complementing it with the local word-level features could bring additional gains. Based on this insight, we propose an approach that combines both the local and global features produced by Transformer models to improve the prediction power of the classifier. Our experiments show that the proposed model either outperforms or is comparable to the state-of-the-art methods on benchmark datasets.