Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Convolutional Representations for Multiscale Human Settlement Detection
Paper and Code
Jul 18, 2017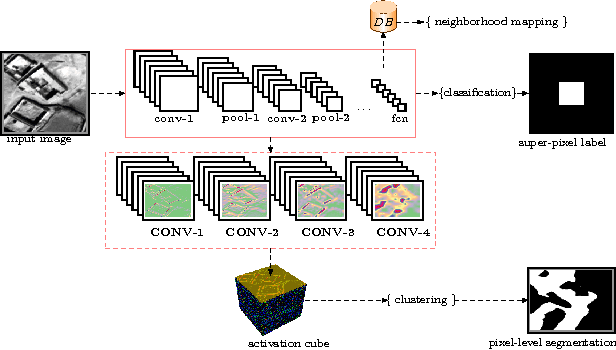

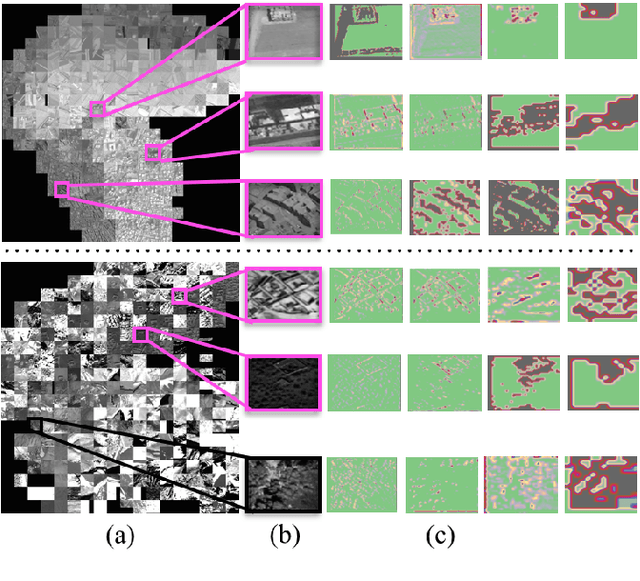
We test this premise and explore representation spaces from a single deep convolutional network and their visualization to argue for a novel unified feature extraction framework. The objective is to utilize and re-purpose trained feature extractors without the need for network retraining on three remote sensing tasks i.e. superpixel mapping, pixel-level segmentation and semantic based image visualization. By leveraging the same convolutional feature extractors and viewing them as visual information extractors that encode different image representation spaces, we demonstrate a preliminary inductive transfer learning potential on multiscale experiments that incorporate edge-level details up to semantic-level information.
* 4 pages, 5 figures, IGARSS 2017
View paper on