 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Class Similarity for Machine Learning with Confidence Labels and Projective Loss Functions
Paper and Code
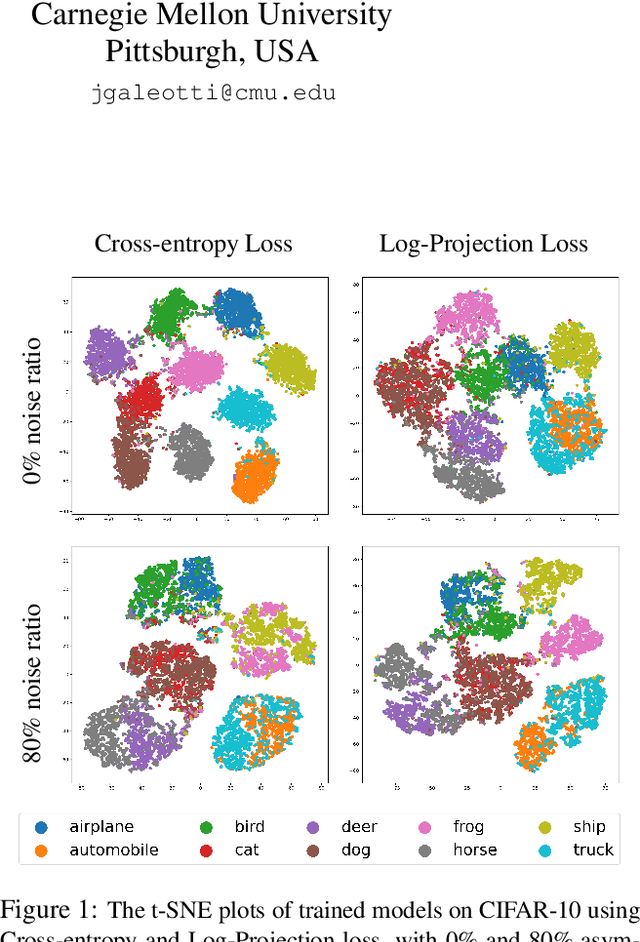
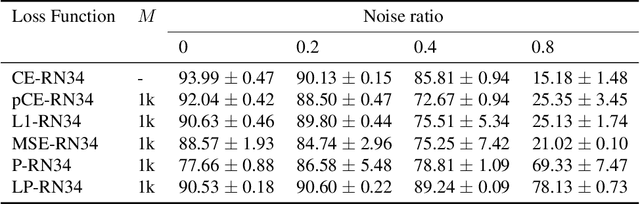
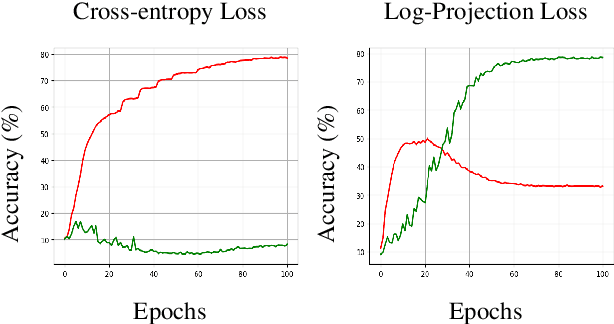
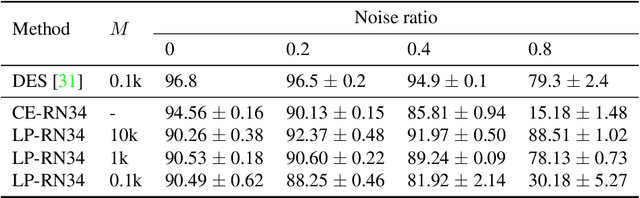
Class labels used for machine learning are relatable to each other, with certain class labels being more similar to each other than others (e.g. images of cats and dogs are more similar to each other than those of cats and cars). Such similarity among classes is often the cause of poor model performance due to the models confusing between them. Current labeling techniques fail to explicitly capture such similarity information. In this paper, we instead exploit the similarity between classes by capturing the similarity information with our novel confidence labels. Confidence labels are probabilistic labels denoting the likelihood of similarity, or confusability, between the classes. Often even after models are trained to differentiate between classes in the feature space, the similar classes' latent space still remains clustered. We view this type of clustering as valuable information and exploit it with our novel projective loss functions. Our projective loss functions are designed to work with confidence labels with an ability to relax the loss penalty for errors that confuse similar classes. We use our approach to train neural networks with noisy labels, as we believe noisy labels are partly a result of confusability arising from class similarity. We show improved performance compared to the use of standard loss functions. We conduct a detailed analysis using the CIFAR-10 dataset and show our proposed methods' applicability to larger datasets, such as ImageNet and Food-101N.