 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting all samples in low-resource sentence classification: early stopping and initialization parameters
Paper and Code
Nov 12, 2021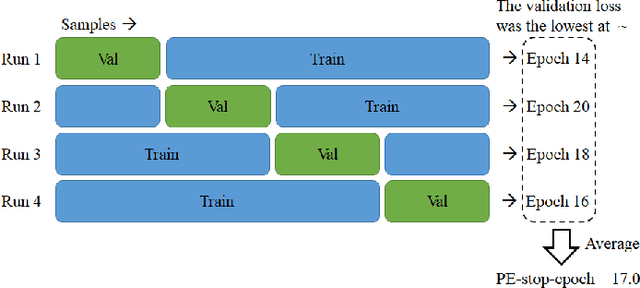
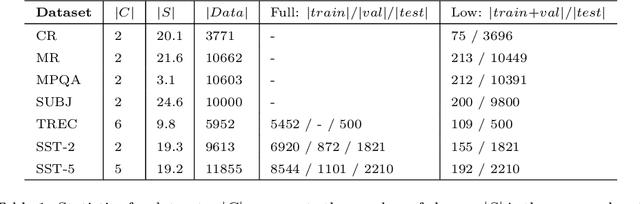
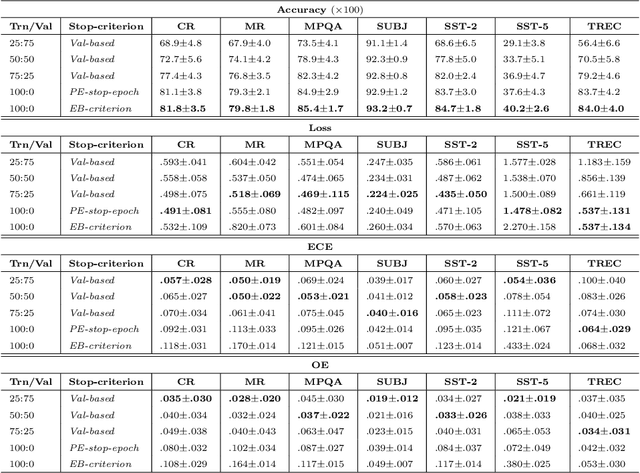
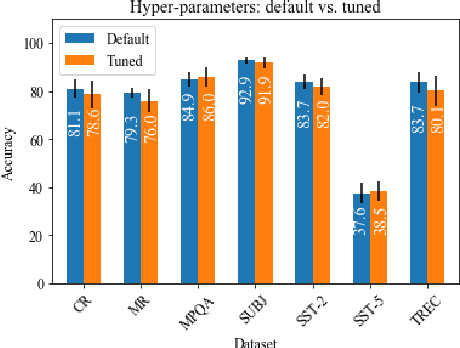
In low resource settings, deep neural models have often shown lower performance due to overfitting. The primary method to solve the overfitting problem is to generalize model parameters. To this end, many researchers have depended on large external resources with various manipulation techniques. In this study, we discuss how to exploit all available samples in low resource settings, without external datasets and model manipulation. This study focuses on natural language processing task. We propose a simple algorithm to find out good initialization parameters that improve robustness to a small sample set. We apply early stopping techniques that enable the use of all samples for training. Finally, the proposed learning strategy is to train all samples with the good initialization parameters and stop the model with the early stopping techniques. Extensive experiments are conducted on seven public sentence classification datasets, and the results demonstrate that the proposed learning strategy achieves better performance than several state-of-the-art works across the seven datasets.