 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Diversity Conditions for Effective Question Answer Generation with Large Language Models
Paper and Code
Jun 26, 2024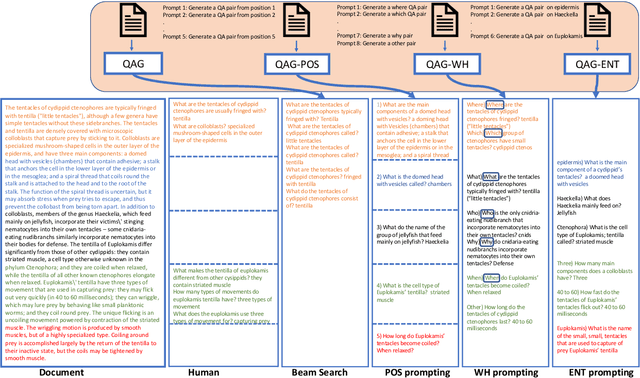

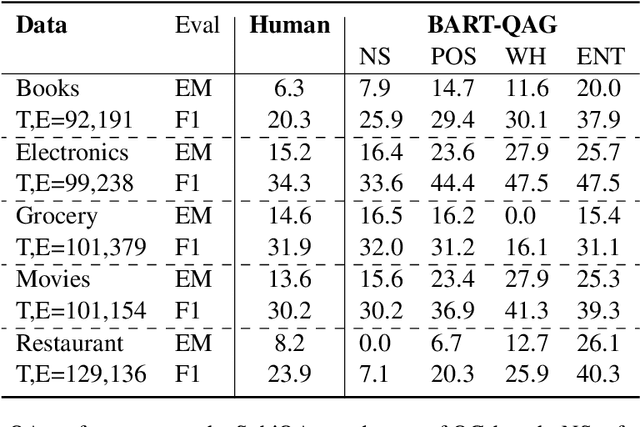

Question Answer Generation (QAG) is an effective data augmentation technique to improve the accuracy of question answering systems, especially in low-resource domains. While recent pretrained and large language model-based QAG methods have made substantial progress, they face the critical issue of redundant QA pair generation, affecting downstream QA systems. Implicit diversity techniques such as sampling and diverse beam search are proven effective solutions but often yield smaller diversity. We present explicit diversity conditions for QAG, focusing on spatial aspects, question types, and entities, substantially increasing diversity in QA generation. Our work emphasizes the need of explicit diversity conditions for generating diverse question-answer synthetic data by showing significant improvements in downstream QA task over existing widely adopted implicit diversity techniques. In particular, generated QA pairs from explicit diversity conditions when used to train the downstream QA model results in an average 4.1% exact match and 4.5% F1 improvement over QAG from implicit sampling techniques on SQuADDU. Our work emphasizes the need for explicit diversity conditions even more in low-resource datasets (SubjQA), where average downstream QA performance improvements are around 12% EM.