 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation-based Counterfactual Retraining(XCR): A Calibration Method for Black-box Models
Paper and Code
Jun 22, 2022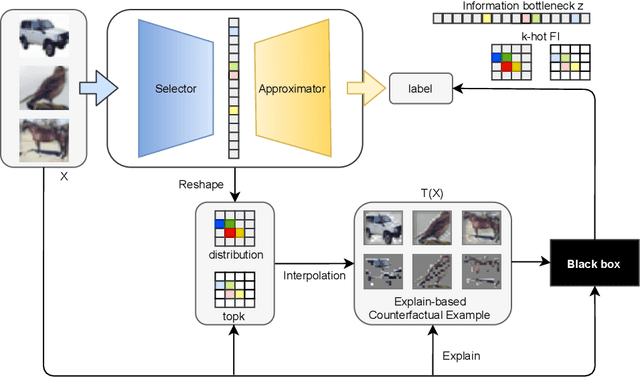



With the rapid development of eXplainable Artificial Intelligence (XAI), a long line of past work has shown concerns about the Out-of-Distribution (OOD) problem in perturbation-based post-hoc XAI models and explanations are socially misaligned. We explore the limitations of post-hoc explanation methods that use approximators to mimic the behavior of black-box models. Then we propose eXplanation-based Counterfactual Retraining (XCR), which extracts feature importance fastly. XCR applies the explanations generated by the XAI model as counterfactual input to retrain the black-box model to address OOD and social misalignment problems. Evaluation of popular image datasets shows that XCR can improve model performance when only retaining 12.5% of the most crucial features without changing the black-box model structure. Furthermore, the evaluation of the benchmark of corruption datasets shows that the XCR is very helpful for improving model robustness and positively impacts the calibration of OOD problems. Even though not calibrated in the validation set like some OOD calibration methods, the corrupted data metric outperforms existing methods. Our method also beats current OOD calibration methods on the OOD calibration metric if calibration on the validation set is applied.