 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining medical AI performance disparities across sites with confounder Shapley value analysis
Paper and Code
Nov 12, 2021

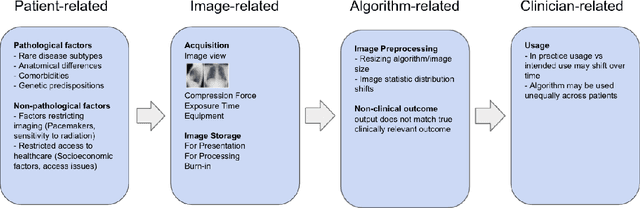

Medical AI algorithms can often experience degraded performance when evaluated on previously unseen sites. Addressing cross-site performance disparities is key to ensuring that AI is equitable and effective when deployed on diverse patient populations. Multi-site evaluations are key to diagnosing such disparities as they can test algorithms across a broader range of potential biases such as patient demographics, equipment types, and technical parameters. However, such tests do not explain why the model performs worse. Our framework provides a method for quantifying the marginal and cumulative effect of each type of bias on the overall performance difference when a model is evaluated on external data. We demonstrate its usefulness in a case study of a deep learning model trained to detect the presence of pneumothorax, where our framework can help explain up to 60% of the discrepancy in performance across different sites with known biases like disease comorbidities and imaging parameters.