 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Adversarial Attacks in Deep Neural Networks Using Activation Profiles
Paper and Code
Mar 18, 2021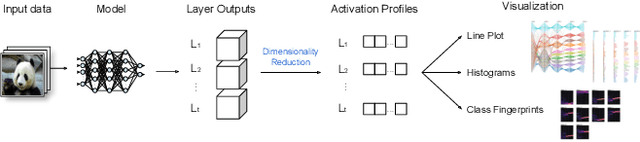


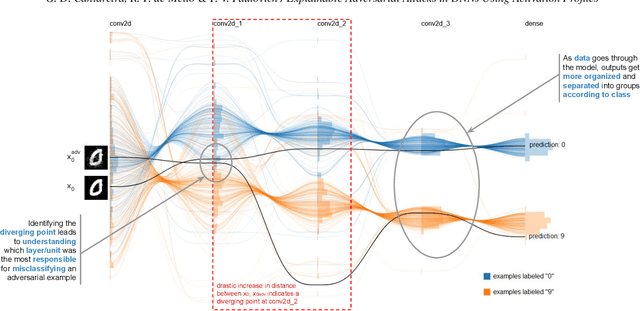
As neural networks become the tool of choice to solve an increasing variety of problems in our society, adversarial attacks become critical. The possibility of generating data instances deliberately designed to fool a network's analysis can have disastrous consequences. Recent work has shown that commonly used methods for model training often result in fragile abstract representations that are particularly vulnerable to such attacks. This paper presents a visual framework to investigate neural network models subjected to adversarial examples, revealing how models' perception of the adversarial data differs from regular data instances and their relationships with class perception. Through different use cases, we show how observing these elements can quickly pinpoint exploited areas in a model, allowing further study of vulnerable features in input data and serving as a guide to improving model training and architecture.