 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability of Deep Learning models for Urban Space perception
Paper and Code

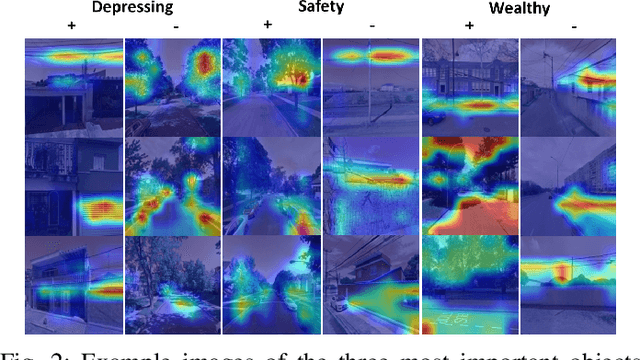
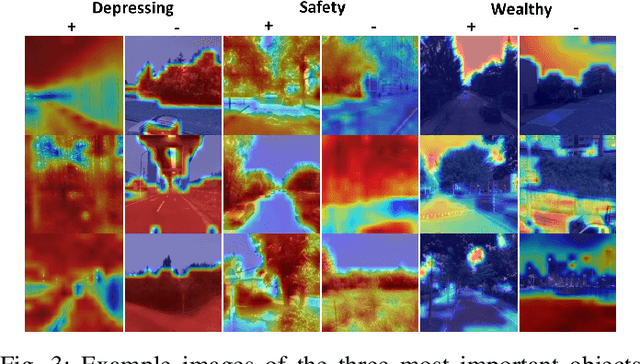
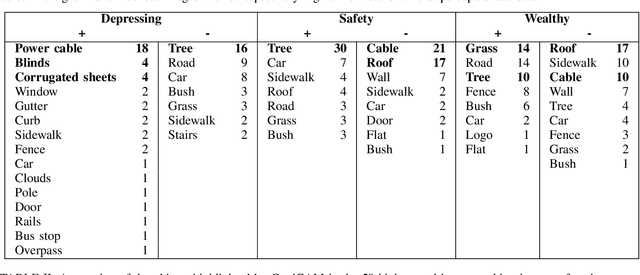
Deep learning based computer vision models are increasingly used by urban planners to support decision making for shaping urban environments. Such models predict how people perceive the urban environment quality in terms of e.g. its safety or beauty. However, the blackbox nature of deep learning models hampers urban planners to understand what landscape objects contribute to a particularly high quality or low quality urban space perception. This study investigates how computer vision models can be used to extract relevant policy information about peoples' perception of the urban space. To do so, we train two widely used computer vision architectures; a Convolutional Neural Network and a transformer, and apply GradCAM -- a well-known ex-post explainable AI technique -- to highlight the image regions important for the model's prediction. Using these GradCAM visualizations, we manually annotate the objects relevant to the models' perception predictions. As a result, we are able to discover new objects that are not represented in present object detection models used for annotation in previous studies. Moreover, our methodological results suggest that transformer architectures are better suited to be used in combination with GradCAM techniques. Code is available on Github.