 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpedition: A System for the Unsupervised Learning of a Hierarchy of Concepts
Paper and Code
Dec 17, 2021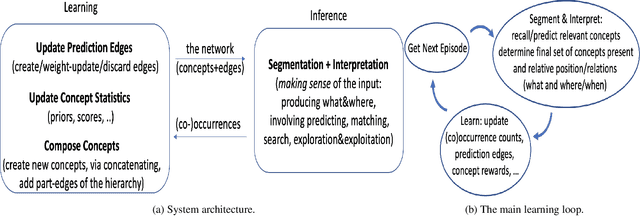



We present a system for bottom-up cumulative learning of myriad concepts corresponding to meaningful character strings, and their part-related and prediction edges. The learning is self-supervised in that the concepts discovered are used as predictors as well as targets of prediction. We devise an objective for segmenting with the learned concepts, derived from comparing to a baseline prediction system, that promotes making and using larger concepts, which in turn allows for predicting larger spans of text, and we describe a simple technique to promote exploration, i.e. trying out newly generated concepts in the segmentation process. We motivate and explain a layering of the concepts, to help separate the (conditional) distributions learnt among concepts. The layering of the concepts roughly corresponds to a part-whole concept hierarchy. With rudimentary segmentation and learning algorithms, the system is promising in that it acquires many concepts (tens of thousands in our small-scale experiments), and it learns to segment text well: when fed with English text with spaces removed, starting at the character level, much of what is learned respects word or phrase boundaries, and over time the average number of "bad" splits within segmentations, i.e. splits inside words, decreases as larger concepts are discovered and the system learns when to use them during segmentation. We report on promising experiments when the input text is converted to binary and the system begins with only two concepts, "0" and "1". The system is transparent, in the sense that it is easy to tell what the concepts learned correspond to, and which ones are active in a segmentation, or how the system "sees" its input. We expect this framework to be extensible and we discuss the current limitations and a number of directions for enhancing the learning and inference capabilities.