Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcuse me, sir? Your language model is leaking
Paper and Code
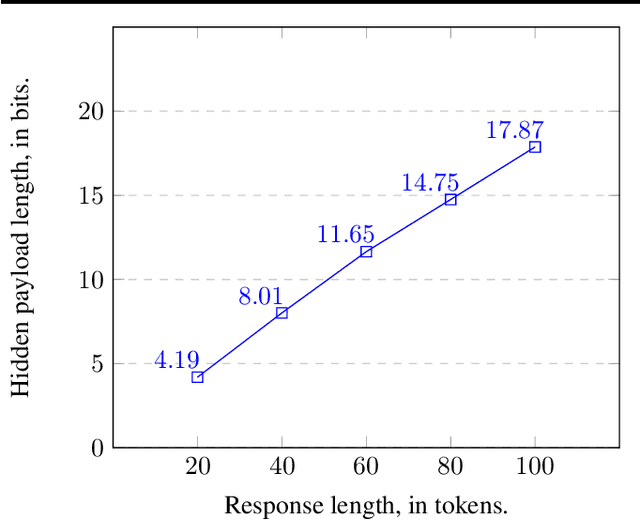

We introduce a cryptographic method to hide an arbitrary secret payload in the response of a Large Language Model (LLM). A secret key is required to extract the payload from the model's response, and without the key it is provably impossible to distinguish between the responses of the original LLM and the LLM that hides a payload. In particular, the quality of generated text is not affected by the payload. Our approach extends a recent result of Christ, Gunn and Zamir (2023) who introduced an undetectable watermarking scheme for LLMs.
View paper on