Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExchangeable Input Representations for Reinforcement Learning
Paper and Code
Mar 19, 2020
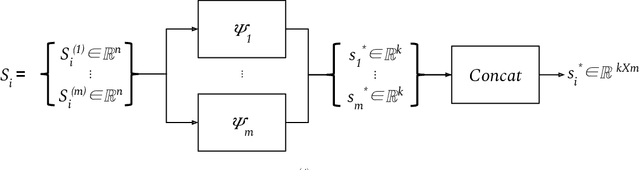
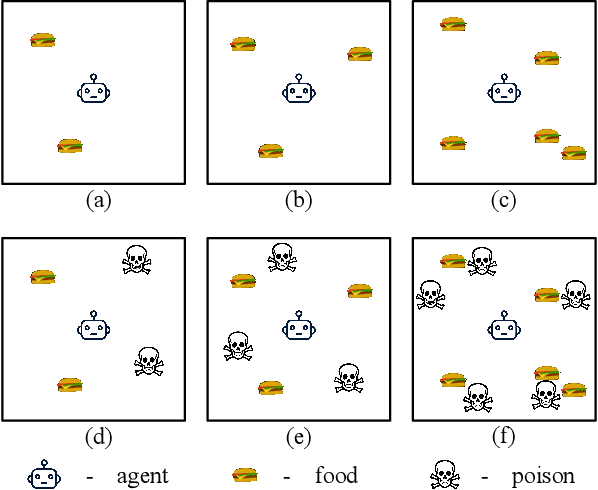

Poor sample efficiency is a major limitation of deep reinforcement learning in many domains. This work presents an attention-based method to project neural network inputs into an efficient representation space that is invariant under changes to input ordering. We show that our proposed representation results in an input space that is a factor of $m!$ smaller for inputs of $m$ objects. We also show that our method is able to represent inputs over variable numbers of objects. Our experiments demonstrate improvements in sample efficiency for policy gradient methods on a variety of tasks. We show that our representation allows us to solve problems that are otherwise intractable when using na\"ive approaches.
* 6 pages, 7 figures
View paper on