 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcess risk bounds in robust empirical risk minimization
Paper and Code
Oct 16, 2019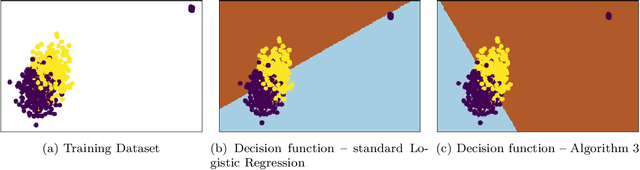
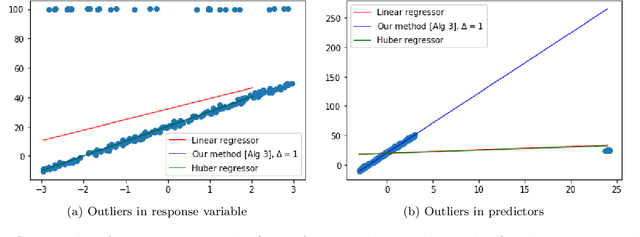
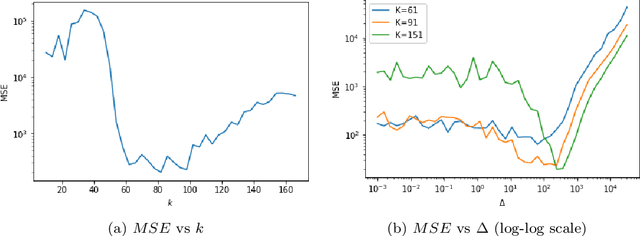
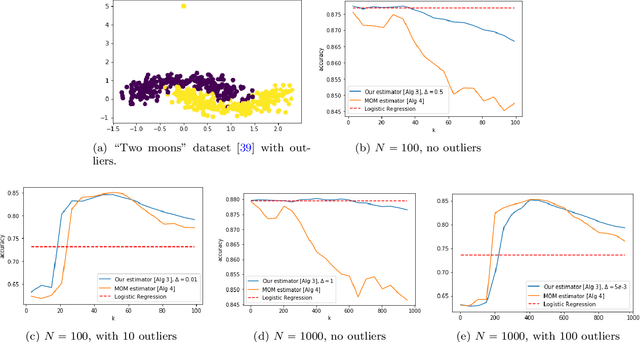
This paper investigates robust versions of the general empirical risk minimization algorithm, one of the core techniques underlying modern statistical methods. Success of the empirical risk minimization is based on the fact that for a "well-behaved" stochastic process $\left\{ f(X), \ f\in \mathcal F\right\}$ indexed by a class of functions $f\in \mathcal F$, averages $\frac{1}{N}\sum_{j=1}^N f(X_j)$ evaluated over a sample $X_1,\ldots,X_N$ of i.i.d. copies of $X$ provide good approximation to the expectations $\mathbb E f(X)$ uniformly over large classes $f\in \mathcal F$. However, this might no longer be true if the marginal distributions of the process are heavy-tailed or if the sample contains outliers. We propose a version of empirical risk minimization based on the idea of replacing sample averages by robust proxies of the expectation, and obtain high-confidence bounds for the excess risk of resulting estimators. In particular, we show that the excess risk of robust estimators can converge to $0$ at fast rates with respect to the sample size. We discuss implications of the main results to the linear and logistic regression problems, and evaluate the numerical performance of proposed methods on simulated and real data.