 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Policy Entropy of Reinforcement Learning Agents for Personalization Tasks
Paper and Code
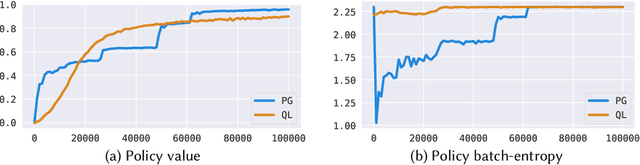



This effort is focused on examining the behavior of reinforcement learning systems in personalization environments and detailing the differences in policy entropy associated with the type of learning algorithm utilized. We demonstrate that Policy Optimization agents often possess low-entropy policies during training, which in practice results in agents prioritizing certain actions and avoiding others. Conversely, we also show that Q-Learning agents are far less susceptible to such behavior and generally maintain high-entropy policies throughout training, which is often preferable in real-world applications. We provide a wide range of numerical experiments as well as theoretical justification to show that these differences in entropy are due to the type of learning being employed.