Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Penalty Method for Federated Learning
Paper and Code
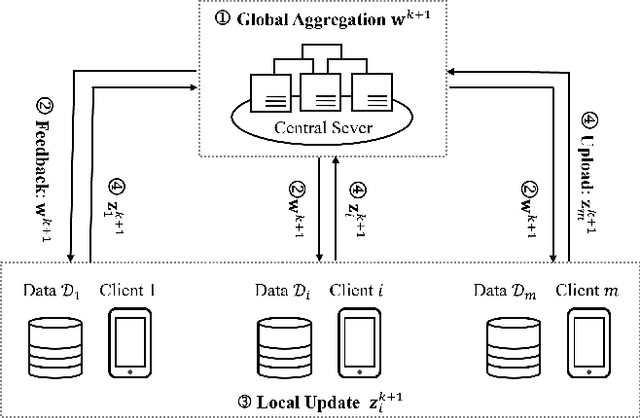
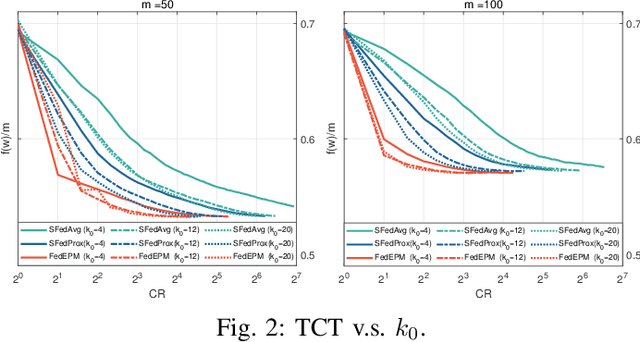
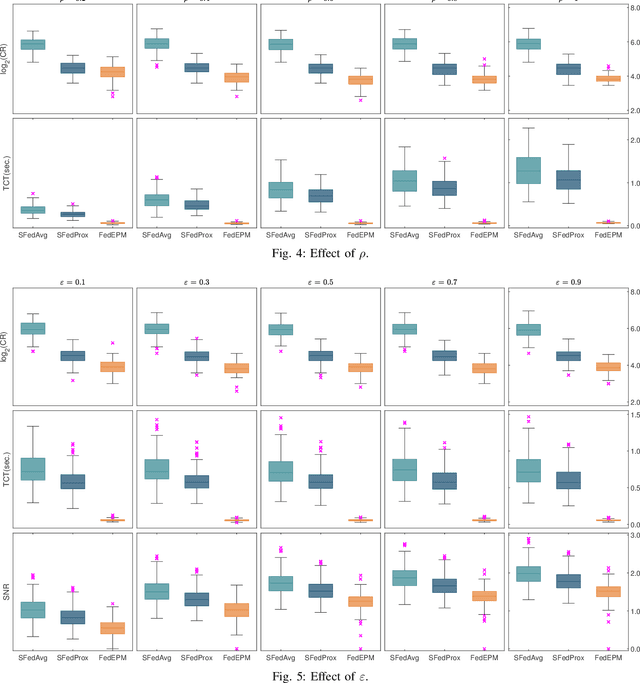
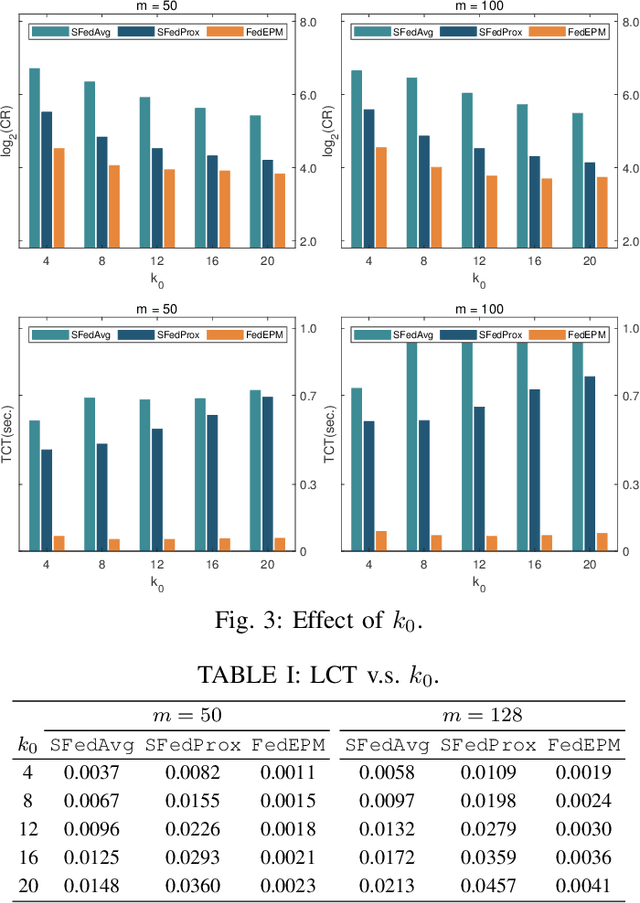
Federated learning has burgeoned recently in machine learning, giving rise to a variety of research topics. Popular optimization algorithms are based on the frameworks of the (stochastic) gradient descent methods or the alternating direction method of multipliers. In this paper, we deploy an exact penalty method to deal with federated learning and propose an algorithm, FedEPM, that enables to tackle four critical issues in federated learning: communication efficiency, computational complexity, stragglers' effect, and data privacy. Moreover, it is proven to be convergent and testified to have high numerical performance.
View paper on