 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Bin Packing for Memory-Efficient Dataflow Inference Acceleration on FPGA
Paper and Code
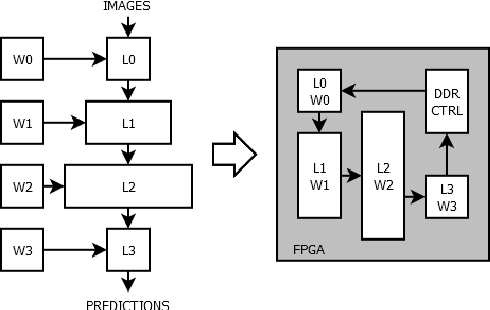
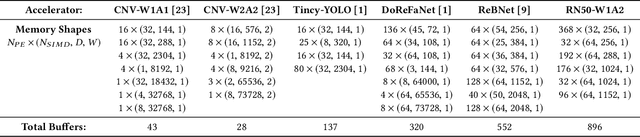
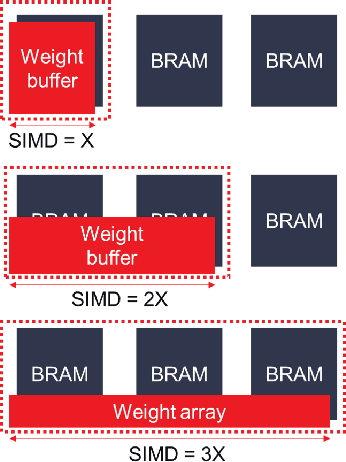
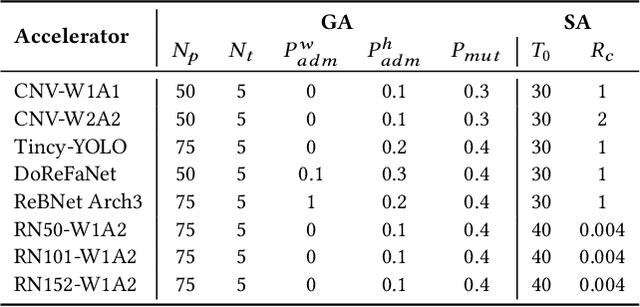
Convolutional neural network (CNN) dataflow inference accelerators implemented in Field Programmable Gate Arrays (FPGAs) have demonstrated increased energy efficiency and lower latency compared to CNN execution on CPUs or GPUs. However, the complex shapes of CNN parameter memories do not typically map well to FPGA on-chip memories (OCM), which results in poor OCM utilization and ultimately limits the size and types of CNNs which can be effectively accelerated on FPGAs. In this work, we present a design methodology that improves the mapping efficiency of CNN parameters to FPGA OCM. We frame the mapping as a bin packing problem and determine that traditional bin packing algorithms are not well suited to solve the problem within FPGA- and CNN-specific constraints. We hybridize genetic algorithms and simulated annealing with traditional bin packing heuristics to create flexible mappers capable of grouping parameter memories such that each group optimally fits FPGA on-chip memories. We evaluate these algorithms on a variety of FPGA inference accelerators. Our hybrid mappers converge to optimal solutions in a matter of seconds for all CNN use-cases, achieve an increase of up to 65% in OCM utilization efficiency for deep CNNs, and are up to 200$\times$ faster than current state-of-the-art simulated annealing approaches.