 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEveryone deserves their voice to be heard: Analyzing Predictive Gender Bias in ASR Models Applied to Dutch Speech Data
Paper and Code
Nov 14, 2024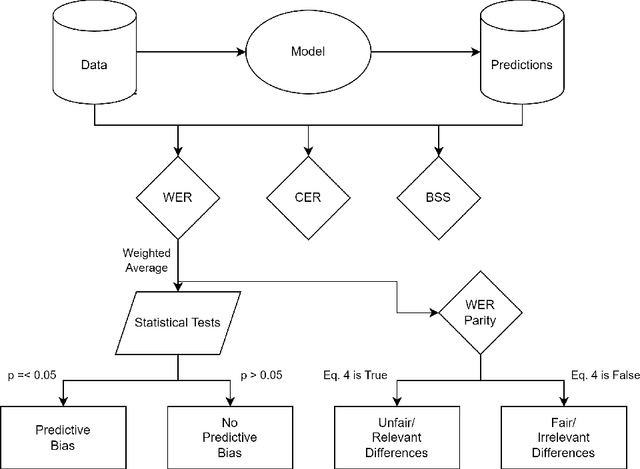
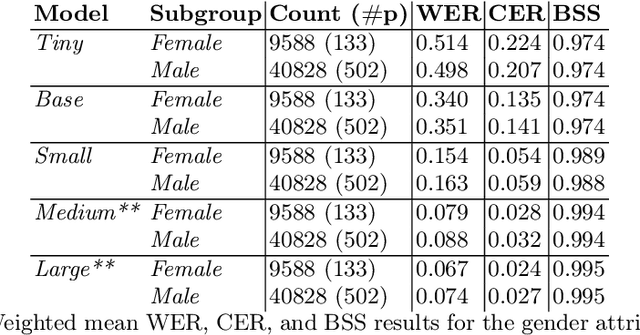
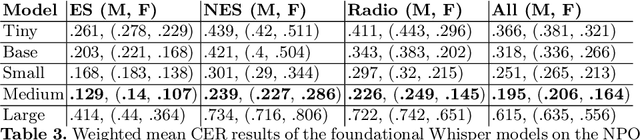
Recent research has shown that state-of-the-art (SotA) Automatic Speech Recognition (ASR) systems, such as Whisper, often exhibit predictive biases that disproportionately affect various demographic groups. This study focuses on identifying the performance disparities of Whisper models on Dutch speech data from the Common Voice dataset and the Dutch National Public Broadcasting organisation. We analyzed the word error rate, character error rate and a BERT-based semantic similarity across gender groups. We used the moral framework of Weerts et al. (2022) to assess quality of service harms and fairness, and to provide a nuanced discussion on the implications of these biases, particularly for automatic subtitling. Our findings reveal substantial disparities in word error rate (WER) among gender groups across all model sizes, with bias identified through statistical testing.