 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Deep-Learning-Based Voice Activity Detectors and Room Impulse Response Models in Reverberant Environments
Paper and Code
Jun 25, 2021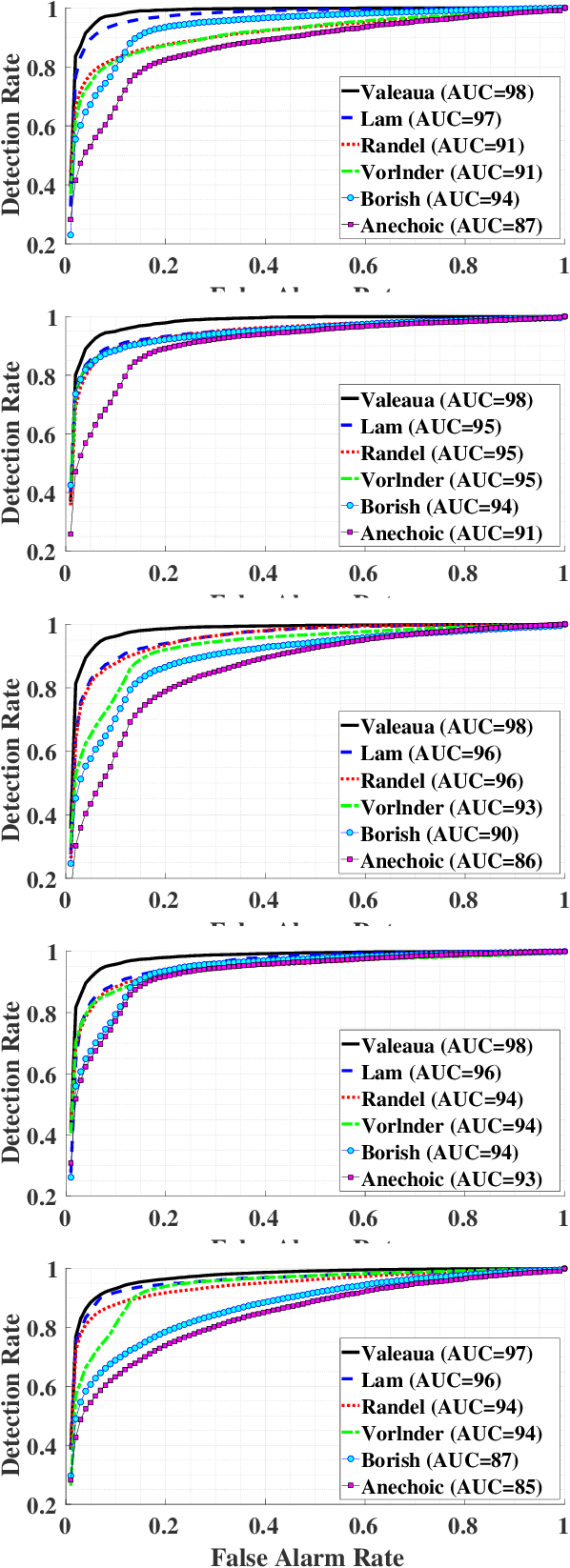
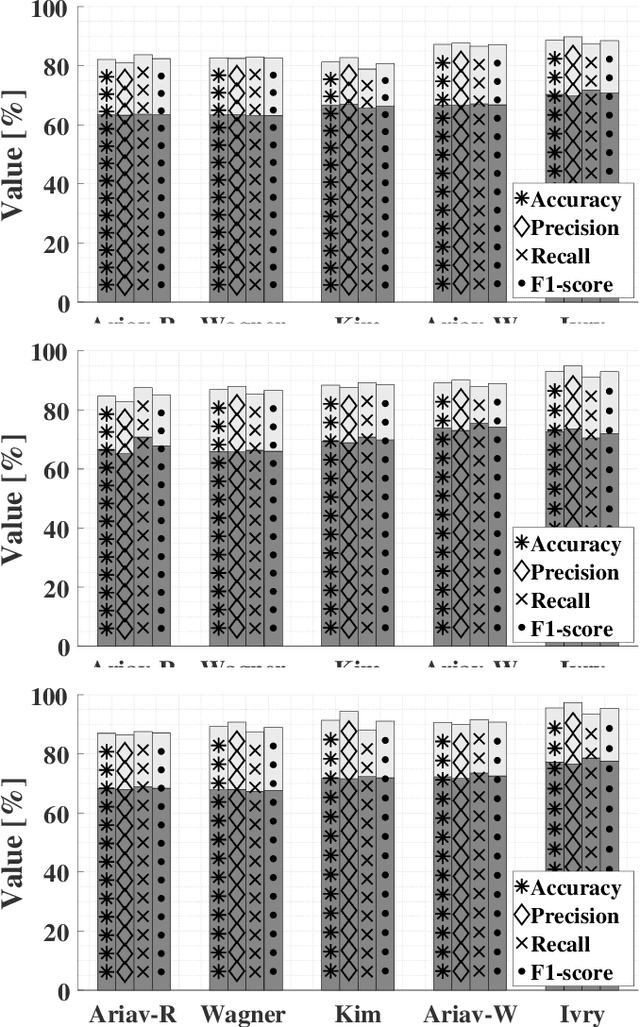
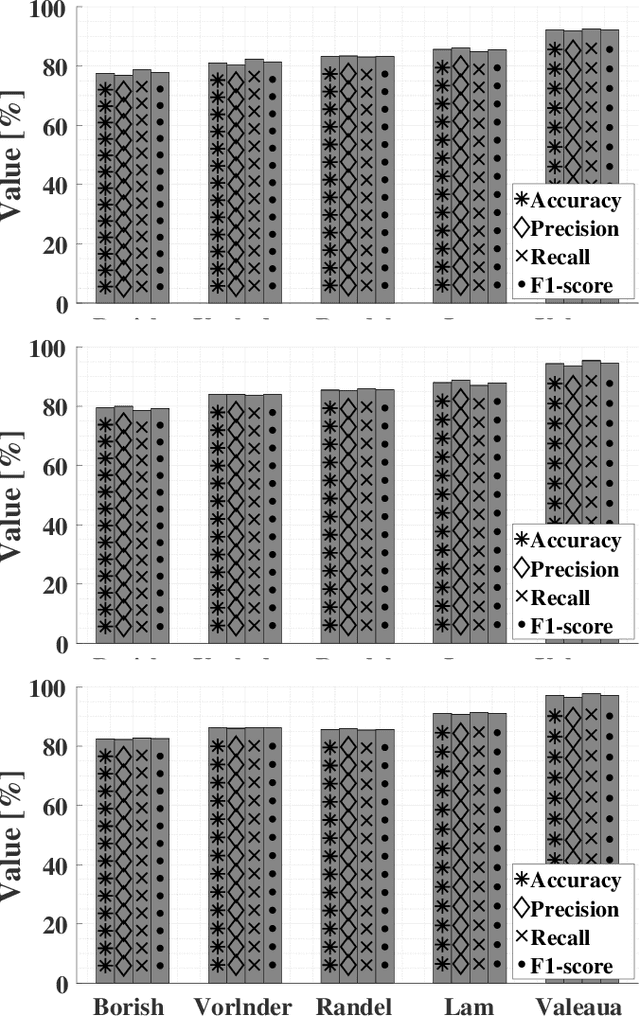
State-of-the-art deep-learning-based voice activity detectors (VADs) are often trained with anechoic data. However, real acoustic environments are generally reverberant, which causes the performance to significantly deteriorate. To mitigate this mismatch between training data and real data, we simulate an augmented training set that contains nearly five million utterances. This extension comprises of anechoic utterances and their reverberant modifications, generated by convolutions of the anechoic utterances with a variety of room impulse responses (RIRs). We consider five different models to generate RIRs, and five different VADs that are trained with the augmented training set. We test all trained systems in three different real reverberant environments. Experimental results show $20\%$ increase on average in accuracy, precision and recall for all detectors and response models, compared to anechoic training. Furthermore, one of the RIR models consistently yields better performance than the other models, for all the tested VADs. Additionally, one of the VADs consistently outperformed the other VADs in all experiments.