Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Zero-Shot Long-Context LLM Compression
Paper and Code
Jun 10, 2024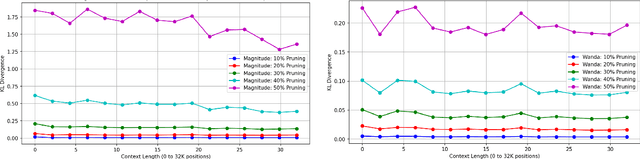


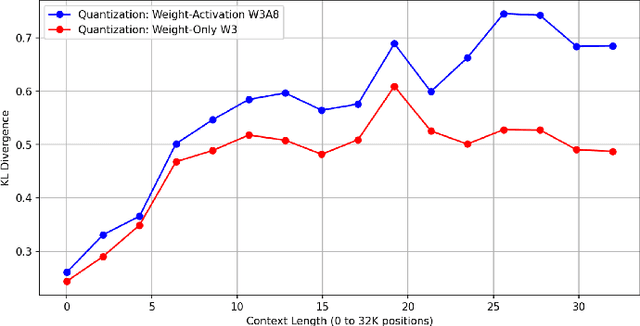
This study evaluates the effectiveness of zero-shot compression techniques on large language models (LLMs) under long-context. We identify the tendency for computational errors to increase under long-context when employing certain compression methods. We propose a hypothesis to explain the varied behavior of different LLM compression techniques and explore remedies to mitigate the performance decline observed in some techniques under long-context. This is a course report for COS 598D Machine Learning and Systems by Prof. Kai Li at Princeton University. Due to limited computational resources, our experiments were conducted only on LLaMA-2-7B-32K.
View paper on