 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Rewards for Question Generation Models
Paper and Code

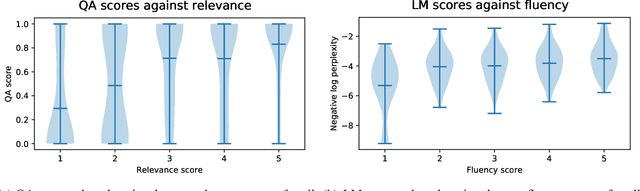


Recent approaches to question generation have used modifications to a Seq2Seq architecture inspired by advances in machine translation. Models are trained using teacher forcing to optimise only the one-step-ahead prediction. However, at test time, the model is asked to generate a whole sequence, causing errors to propagate through the generation process (exposure bias). A number of authors have proposed countering this bias by optimising for a reward that is less tightly coupled to the training data, using reinforcement learning. We optimise directly for quality metrics, including a novel approach using a discriminator learned directly from the training data. We confirm that policy gradient methods can be used to decouple training from the ground truth, leading to increases in the metrics used as rewards. We perform a human evaluation, and show that although these metrics have previously been assumed to be good proxies for question quality, they are poorly aligned with human judgement and the model simply learns to exploit the weaknesses of the reward source.