 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating resampling methods on a real-life highly imbalanced online credit card payments dataset
Paper and Code
Jun 27, 2022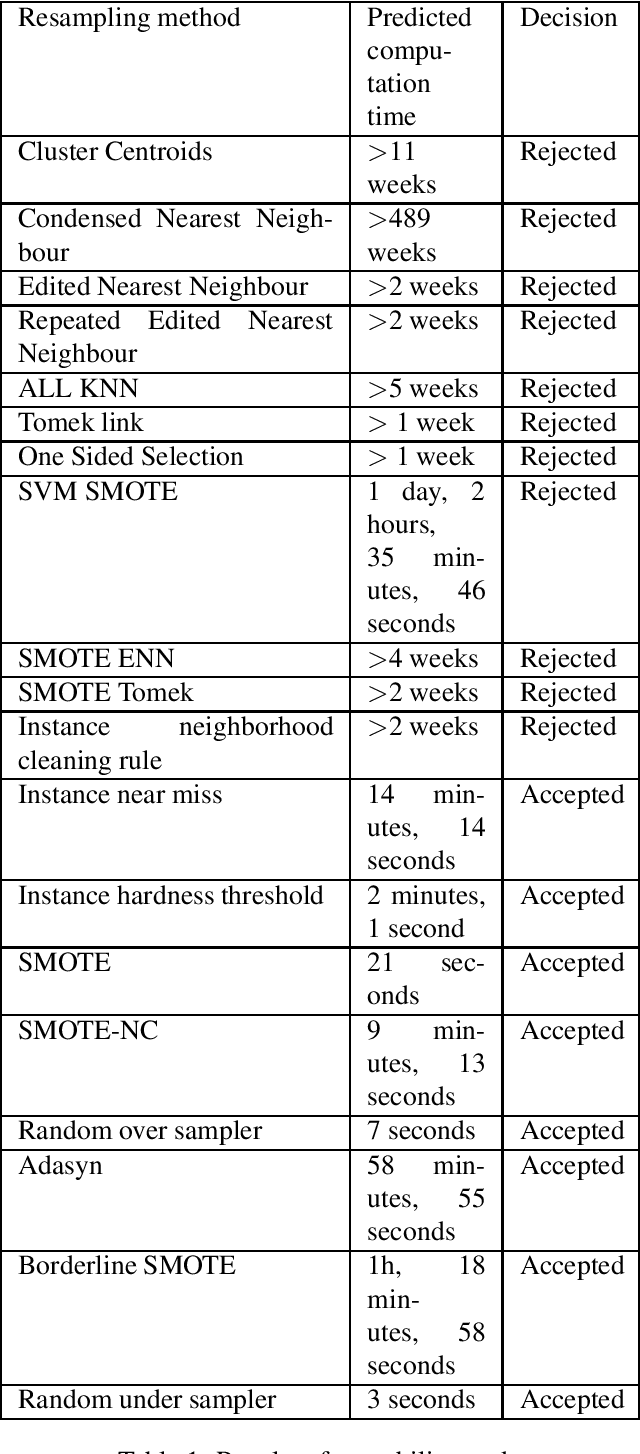

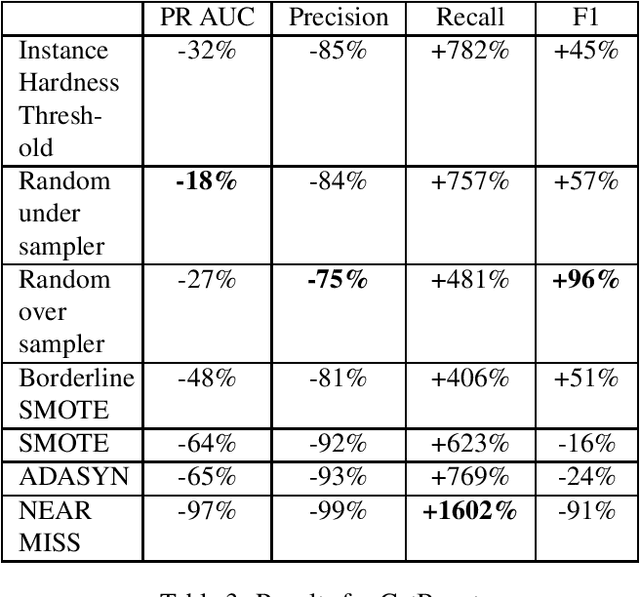

Various problems of any credit card fraud detection based on machine learning come from the imbalanced aspect of transaction datasets. Indeed, the number of frauds compared to the number of regular transactions is tiny and has been shown to damage learning performances, e.g., at worst, the algorithm can learn to classify all the transactions as regular. Resampling methods and cost-sensitive approaches are known to be good candidates to leverage this issue of imbalanced datasets. This paper evaluates numerous state-of-the-art resampling methods on a large real-life online credit card payments dataset. We show they are inefficient because methods are intractable or because metrics do not exhibit substantial improvements. Our work contributes to this domain in (1) that we compare many state-of-the-art resampling methods on a large-scale dataset and in (2) that we use a real-life online credit card payments dataset.