 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLP Methods: Challenges and Approaches
Paper and Code
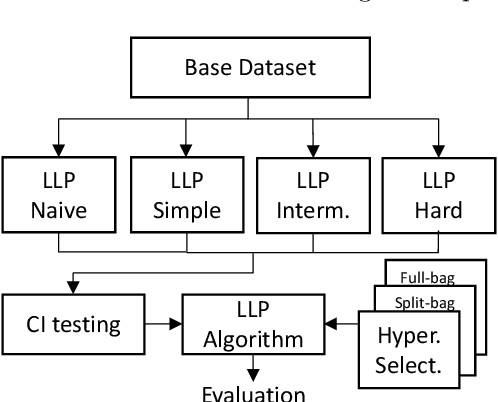
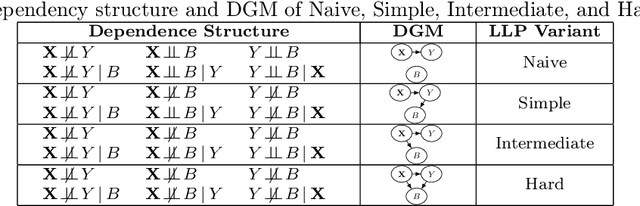
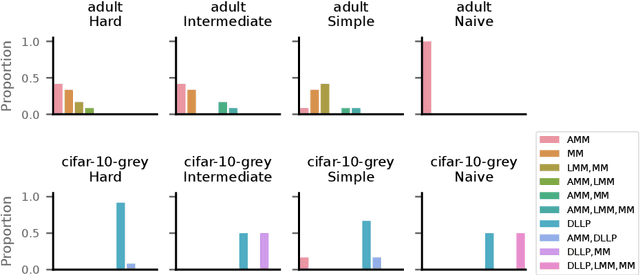
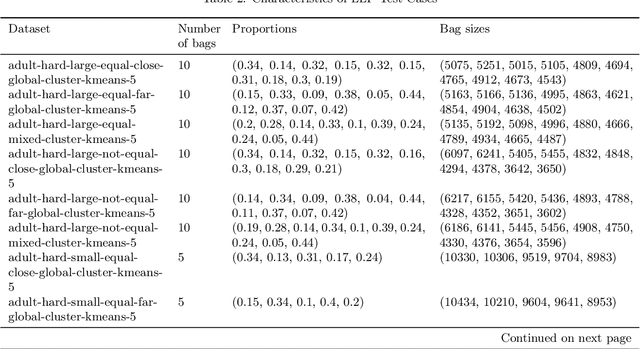
Learning from Label Proportions (LLP) is an established machine learning problem with numerous real-world applications. In this setting, data items are grouped into bags, and the goal is to learn individual item labels, knowing only the features of the data and the proportions of labels in each bag. Although LLP is a well-established problem, it has several unusual aspects that create challenges for benchmarking learning methods. Fundamental complications arise because of the existence of different LLP variants, i.e., dependence structures that can exist between items, labels, and bags. Accordingly, the first algorithmic challenge is the generation of variant-specific datasets capturing the diversity of dependence structures and bag characteristics. The second methodological challenge is model selection, i.e., hyperparameter tuning; due to the nature of LLP, model selection cannot easily use the standard machine learning paradigm. The final benchmarking challenge consists of properly evaluating LLP solution methods across various LLP variants. We note that there is very little consideration of these issues in prior work, and there are no general solutions for these challenges proposed to date. To address these challenges, we develop methods capable of generating LLP datasets meeting the requirements of different variants. We use these methods to generate a collection of datasets encompassing the spectrum of LLP problem characteristics, which can be used in future evaluation studies. Additionally, we develop guidelines for benchmarking LLP algorithms, including the model selection and evaluation steps. Finally, we illustrate the new methods and guidelines by performing an extensive benchmark of a set of well-known LLP algorithms. We show that choosing the best algorithm depends critically on the LLP variant and model selection method, demonstrating the need for our proposed approach.