Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating KGR10 Polish word embeddings in the recognition of temporal expressions using BiLSTM-CRF
Paper and Code


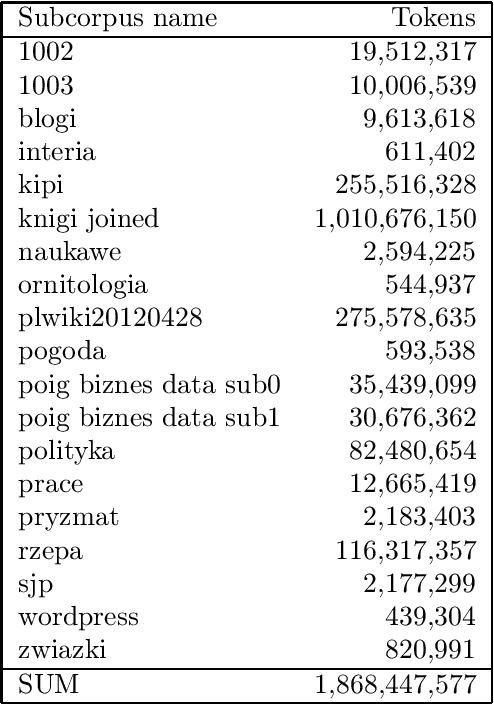

The article introduces a new set of Polish word embeddings, built using KGR10 corpus, which contains more than 4 billion words. These embeddings are evaluated in the problem of recognition of temporal expressions (timexes) for the Polish language. We described the process of KGR10 corpus creation and a new approach to the recognition problem using Bidirectional Long-Short Term Memory (BiLSTM) network with additional CRF layer, where specific embeddings are essential. We presented experiments and conclusions drawn from them.
* Presented at TFML 2019 (Theoretical Foundations of Machine Learning)
View paper on