 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Lingual Transfer Learning Approaches in Multilingual Conversational Agent Models
Paper and Code
Dec 07, 2020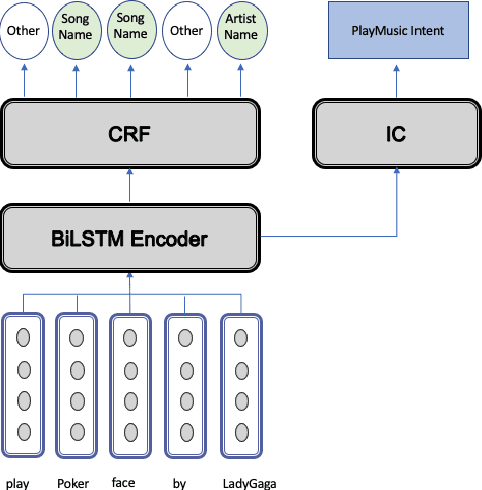
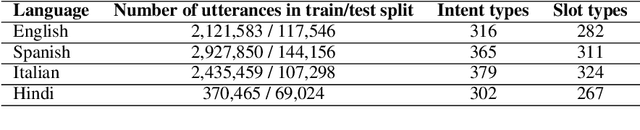
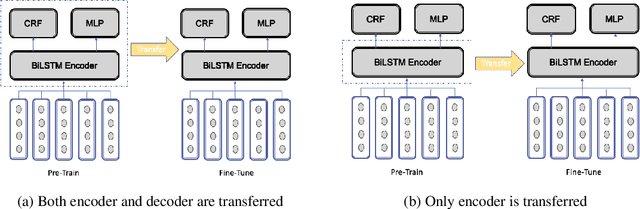

With the recent explosion in popularity of voice assistant devices, there is a growing interest in making them available to user populations in additional countries and languages. However, to provide the highest accuracy and best performance for specific user populations, most existing voice assistant models are developed individually for each region or language, which requires linear investment of effort. In this paper, we propose a general multilingual model framework for Natural Language Understanding (NLU) models, which can help bootstrap new language models faster and reduce the amount of effort required to develop each language separately. We explore how different deep learning architectures affect multilingual NLU model performance. Our experimental results show that these multilingual models can reach same or better performance compared to monolingual models across language-specific test data while require less effort in creating features and model maintenance.