 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating categorical encoding methods on a real credit card fraud detection database
Paper and Code
Dec 22, 2021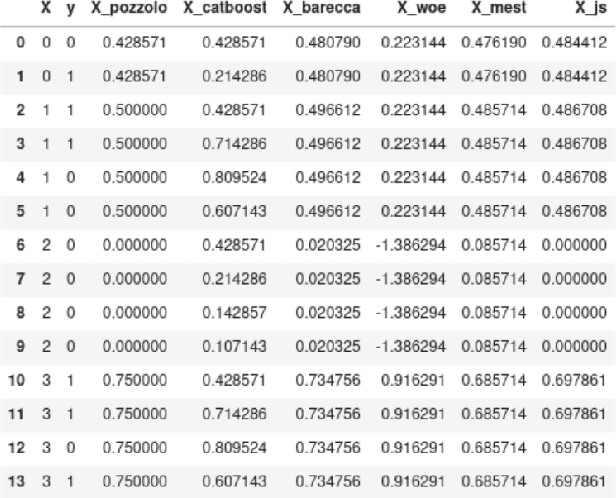
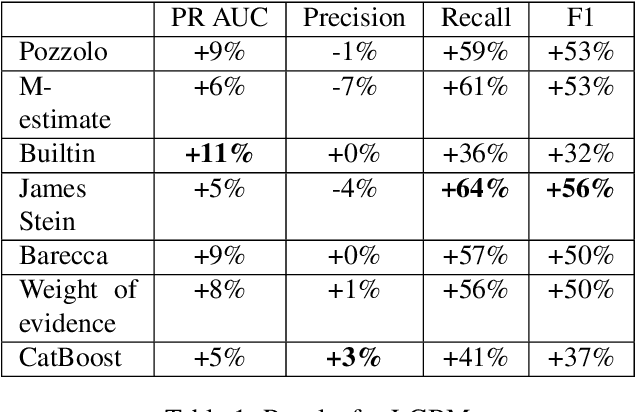
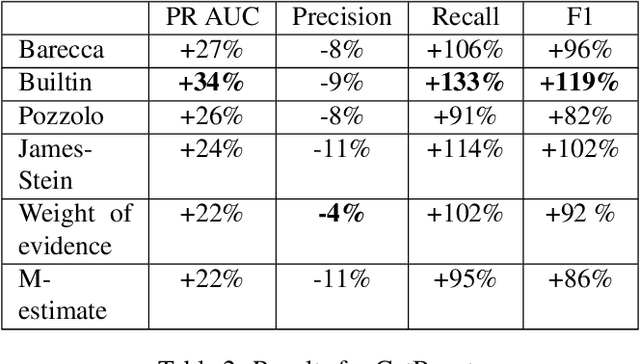

Correctly dealing with categorical data in a supervised learning context is still a major issue. Furthermore, though some machine learning methods embody builtin methods to deal with categorical features, it is unclear whether they bring some improvements and how do they compare with usual categorical encoding methods. In this paper, we describe several well-known categorical encoding methods that are based on target statistics and weight of evidence. We apply them on a large and real credit card fraud detection database. Then, we train the encoded databases using state-of-the-art gradient boosting methods and evaluate their performances. We show that categorical encoding methods generally bring substantial improvements with respect to the absence of encoding. The contribution of this work is twofold: (1) we compare many state-of-the-art "lite" categorical encoding methods on a large scale database and (2) we use a real credit card fraud detection database.