Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEval all, trust a few, do wrong to none: Comparing sentence generation models
Paper and Code
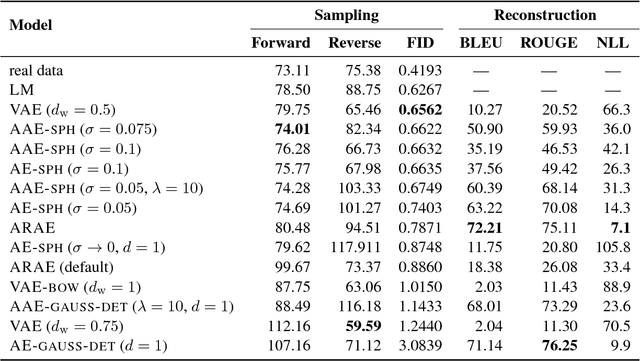
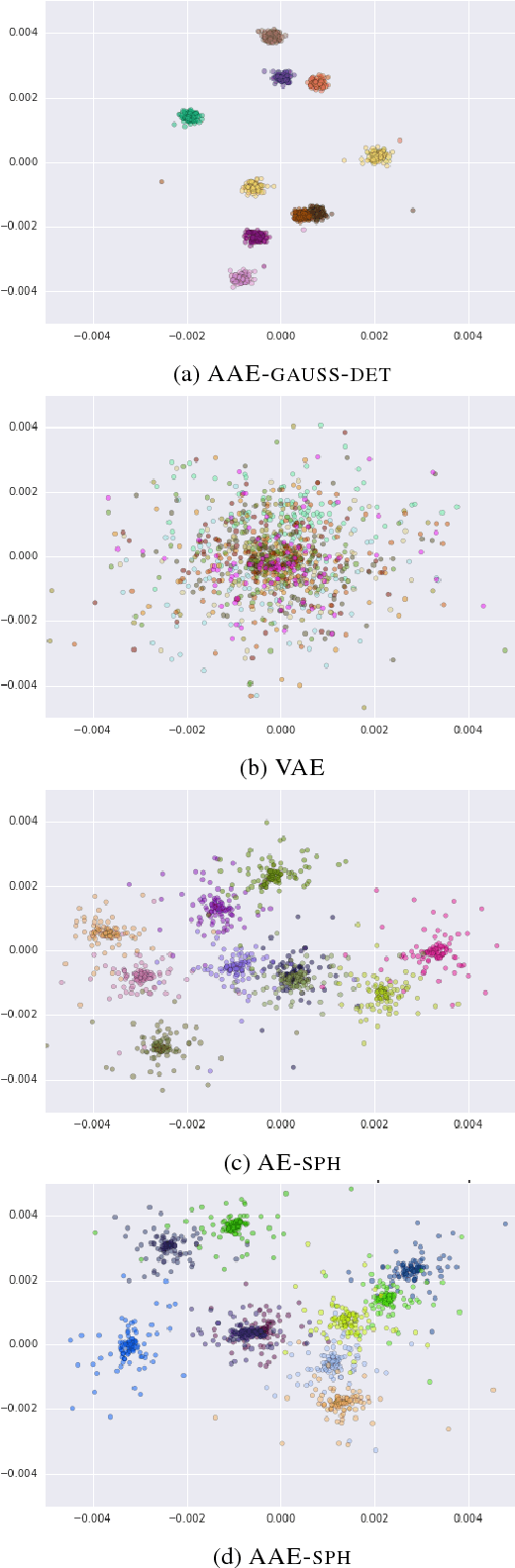


In this paper, we study recent neural generative models for text generation related to variational autoencoders. Previous works have employed various techniques to control the prior distribution of the latent codes in these models, which is important for sampling performance, but little attention has been paid to reconstruction error. In our study, we follow a rigorous evaluation protocol using a large set of previously used and novel automatic and human evaluation metrics, applied to both generated samples and reconstructions. We hope that it will become the new evaluation standard when comparing neural generative models for text.
* 12 pages (3 page appendix); v2: added hyperparameter settings,
clarifications
View paper on