 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEV-SegNet: Semantic Segmentation for Event-based Cameras
Paper and Code
Nov 29, 2018


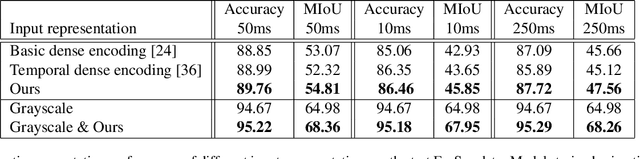
Event cameras, or Dynamic Vision Sensor (DVS), are very promising sensors which have shown several advantages over frame based cameras. However, most recent work on real applications of these cameras is focused on 3D reconstruction and 6-DOF camera tracking. Deep learning based approaches, which are leading the state-of-the-art in visual recognition tasks, could potentially take advantage of the benefits of DVS, but some adaptations are needed still needed in order to effectively work on these cameras. This work introduces a first baseline for semantic segmentation with this kind of data. We build a semantic segmentation CNN based on state-of-the-art techniques which takes event information as the only input. Besides, we propose a novel representation for DVS data that outperforms previously used event representations for related tasks. Since there is no existing labeled dataset for this task, we propose how to automatically generate approximated semantic segmentation labels for some sequences of the DDD17 dataset, which we publish together with the model, and demonstrate they are valid to train a model for DVS data only. We compare our results on semantic segmentation from DVS data with results using corresponding grayscale images, demonstrating how they are complementary and worth combining.