 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Exoplanet Mass using Machine Learning on Incomplete Datasets
Paper and Code
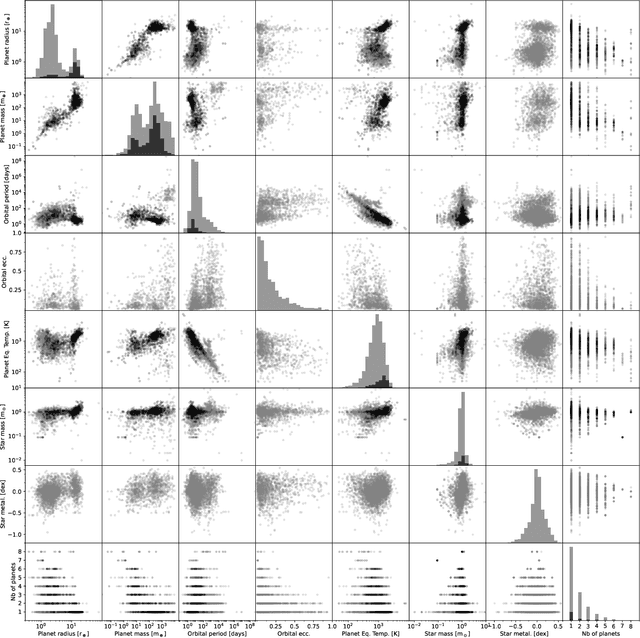

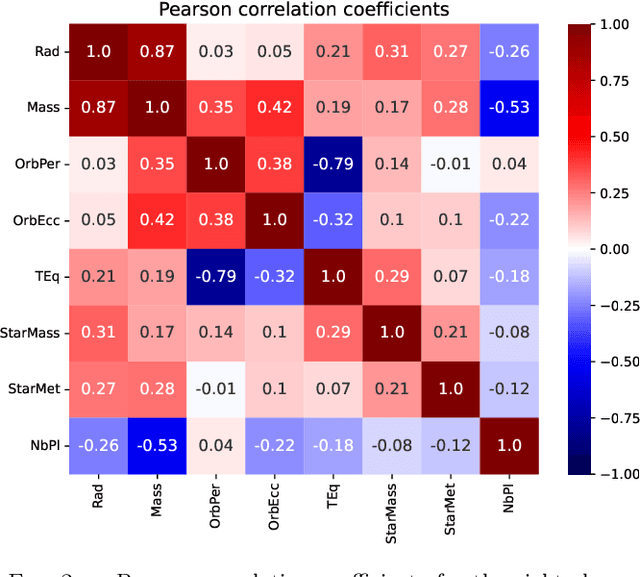
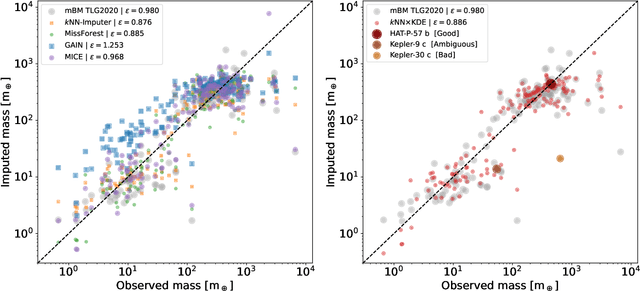
The exoplanet archive is an incredible resource of information on the properties of discovered extrasolar planets, but statistical analysis has been limited by the number of missing values. One of the most informative bulk properties is planet mass, which is particularly challenging to measure with more than 70\% of discovered planets with no measured value. We compare the capabilities of five different machine learning algorithms that can utilize multidimensional incomplete datasets to estimate missing properties for imputing planet mass. The results are compared when using a partial subset of the archive with a complete set of six planet properties, and where all planet discoveries are leveraged in an incomplete set of six and eight planet properties. We find that imputation results improve with more data even when the additional data is incomplete, and allows a mass prediction for any planet regardless of which properties are known. Our favored algorithm is the newly developed $k$NN$\times$KDE, which can return a probability distribution for the imputed properties. The shape of this distribution can indicate the algorithm's level of confidence, and also inform on the underlying demographics of the exoplanet population. We demonstrate how the distributions can be interpreted with a series of examples for planets where the discovery was made with either the transit method, or radial velocity method. Finally, we test the generative capability of the $k$NN$\times$KDE to create a large synthetic population of planets based on the archive, and identify potential categories of planets from groups of properties in the multidimensional space. All codes are Open Source.