 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Prediction of Emotional Experience in Movies using Deep Neural Networks: The Significance of Audio and Language
Paper and Code
Jun 17, 2023
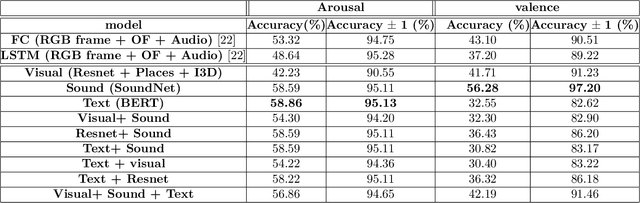


Our paper focuses on making use of deep neural network models to accurately predict the range of human emotions experienced during watching movies. In this certain setup, there exist three clear-cut input modalities that considerably influence the experienced emotions: visual cues derived from RGB video frames, auditory components encompassing sounds, speech, and music, and linguistic elements encompassing actors' dialogues. Emotions are commonly described using a two-factor model including valence (ranging from happy to sad) and arousal (indicating the intensity of the emotion). In this regard, a Plethora of works have presented a multitude of models aiming to predict valence and arousal from video content. However, non of these models contain all three modalities, with language being consistently eliminated across all of them. In this study, we comprehensively combine all modalities and conduct an analysis to ascertain the importance of each in predicting valence and arousal. Making use of pre-trained neural networks, we represent each input modality in our study. In order to process visual input, we employ pre-trained convolutional neural networks to recognize scenes[1], objects[2], and actions[3,4]. For audio processing, we utilize a specialized neural network designed for handling sound-related tasks, namely SoundNet[5]. Finally, Bidirectional Encoder Representations from Transformers (BERT) models are used to extract linguistic features[6] in our analysis. We report results on the COGNIMUSE dataset[7], where our proposed model outperforms the current state-of-the-art approaches. Surprisingly, our findings reveal that language significantly influences the experienced arousal, while sound emerges as the primary determinant for predicting valence. In contrast, the visual modality exhibits the least impact among all modalities in predicting emotions.