 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Segment-Based Speech Emotion Recognition by Deep Self-Learning
Paper and Code
Mar 30, 2021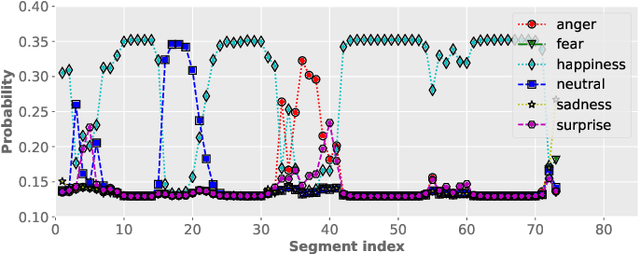
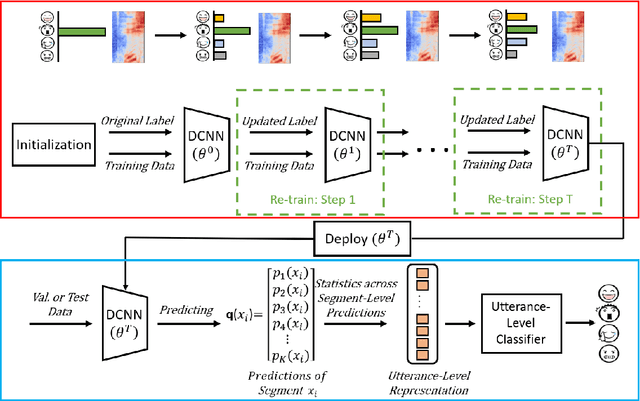

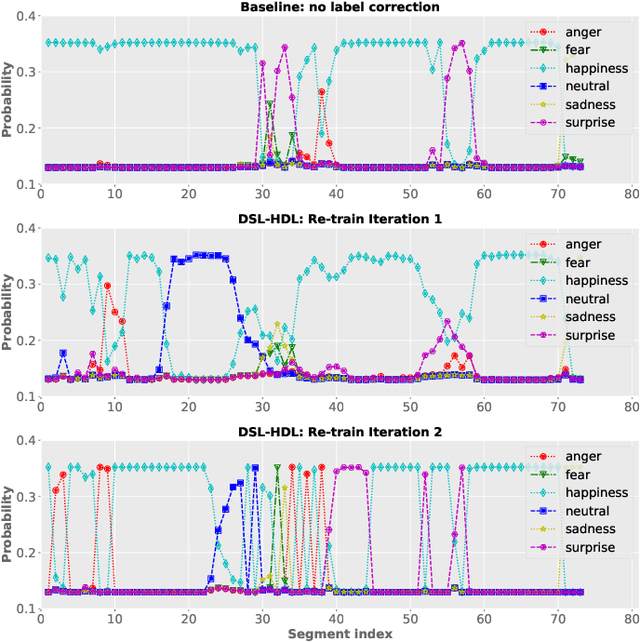
Despite the widespread utilization of deep neural networks (DNNs) for speech emotion recognition (SER), they are severely restricted due to the paucity of labeled data for training. Recently, segment-based approaches for SER have been evolving, which train backbone networks on shorter segments instead of whole utterances, and thus naturally augments training examples without additional resources. However, one core challenge remains for segment-based approaches: most emotional corpora do not provide ground-truth labels at the segment level. To supervisely train a segment-based emotion model on such datasets, the most common way assigns each segment the corresponding utterance's emotion label. However, this practice typically introduces noisy (incorrect) labels as emotional information is not uniformly distributed across the whole utterance. On the other hand, DNNs have been shown to easily over-fit a dataset when being trained with noisy labels. To this end, this work proposes a simple and effective deep self-learning (DSL) framework, which comprises a procedure to progressively correct segment-level labels in an iterative learning manner. The DSL method produces dynamically-generated and soft emotion labels, leading to significant performance improvements. Experiments on three well-known emotional corpora demonstrate noticeable gains using the proposed method.