 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sample Efficiency and Exploration in Reinforcement Learning through the Integration of Diffusion Models and Proximal Policy Optimization
Paper and Code
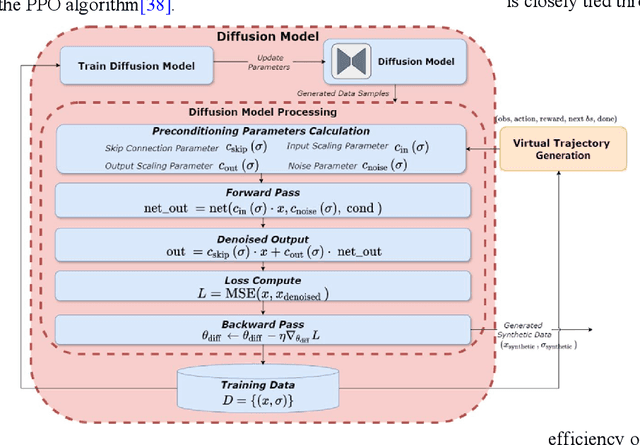
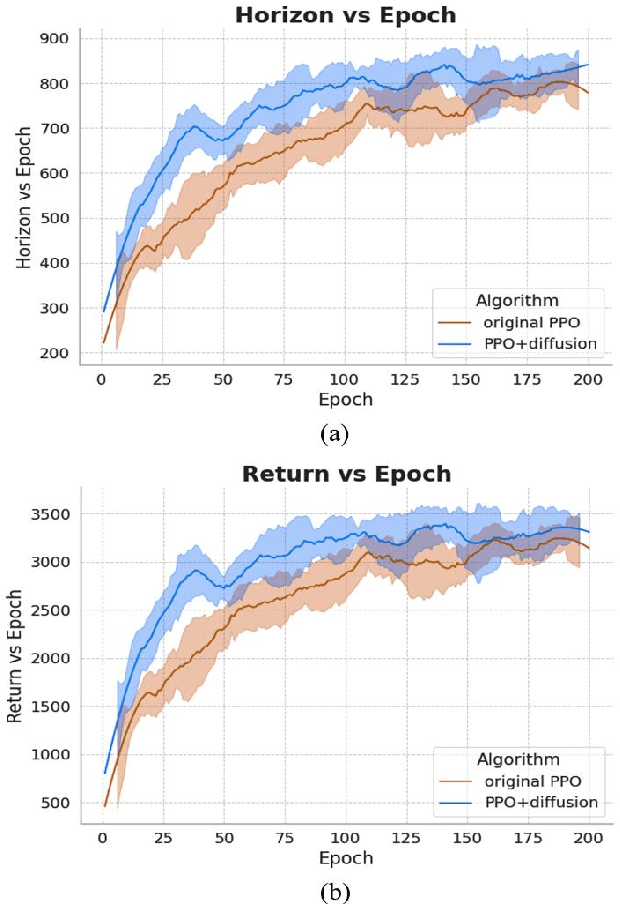


Recent advancements in reinforcement learning (RL) have been fueled by large-scale data and deep neural networks, particularly for high-dimensional and complex tasks. Online RL methods like Proximal Policy Optimization (PPO) are effective in dynamic scenarios but require substantial real-time data, posing challenges in resource-constrained or slow simulation environments. Offline RL addresses this by pre-learning policies from large datasets, though its success depends on the quality and diversity of the data. This work proposes a framework that enhances PPO algorithms by incorporating a diffusion model to generate high-quality virtual trajectories for offline datasets. This approach improves exploration and sample efficiency, leading to significant gains in cumulative rewards, convergence speed, and strategy stability in complex tasks. Our contributions are threefold: we explore the potential of diffusion models in RL, particularly for offline datasets, extend the application of online RL to offline environments, and experimentally validate the performance improvements of PPO with diffusion models. These findings provide new insights and methods for applying RL to high-dimensional, complex tasks. Finally, we open-source our code at https://github.com/TianciGao/DiffPPO