 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Legal Case Retrieval via Scaling High-quality Synthetic Query-Candidate Pairs
Paper and Code


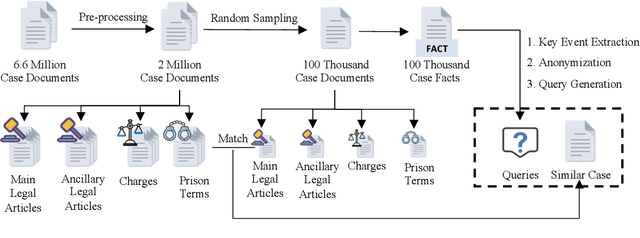

Legal case retrieval (LCR) aims to provide similar cases as references for a given fact description. This task is crucial for promoting consistent judgments in similar cases, effectively enhancing judicial fairness and improving work efficiency for judges. However, existing works face two main challenges for real-world applications: existing works mainly focus on case-to-case retrieval using lengthy queries, which does not match real-world scenarios; and the limited data scale, with current datasets containing only hundreds of queries, is insufficient to satisfy the training requirements of existing data-hungry neural models. To address these issues, we introduce an automated method to construct synthetic query-candidate pairs and build the largest LCR dataset to date, LEAD, which is hundreds of times larger than existing datasets. This data construction method can provide ample training signals for LCR models. Experimental results demonstrate that model training with our constructed data can achieve state-of-the-art results on two widely-used LCR benchmarks. Besides, the construction method can also be applied to civil cases and achieve promising results. The data and codes can be found in https://github.com/thunlp/LEAD.