 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Bidirectional Sign Language Communication: Integrating YOLOv8 and NLP for Real-Time Gesture Recognition & Translation
Paper and Code
Nov 18, 2024
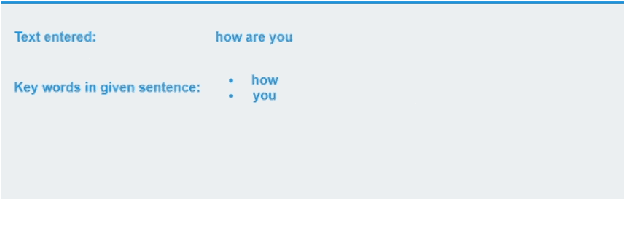


The primary concern of this research is to take American Sign Language (ASL) data through real time camera footage and be able to convert the data and information into text. Adding to that, we are also putting focus on creating a framework that can also convert text into sign language in real time which can help us break the language barrier for the people who are in need. In this work, for recognising American Sign Language (ASL), we have used the You Only Look Once(YOLO) model and Convolutional Neural Network (CNN) model. YOLO model is run in real time and automatically extracts discriminative spatial-temporal characteristics from the raw video stream without the need for any prior knowledge, eliminating design flaws. The CNN model here is also run in real time for sign language detection. We have introduced a novel method for converting text based input to sign language by making a framework that will take a sentence as input, identify keywords from that sentence and then show a video where sign language is performed with respect to the sentence given as input in real time. To the best of our knowledge, this is a rare study to demonstrate bidirectional sign language communication in real time in the American Sign Language (ASL).