 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing AI-based Generation of Software Exploits with Contextual Information
Paper and Code
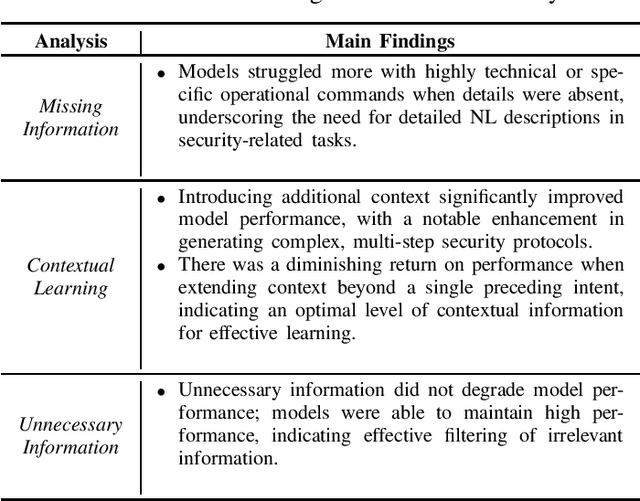
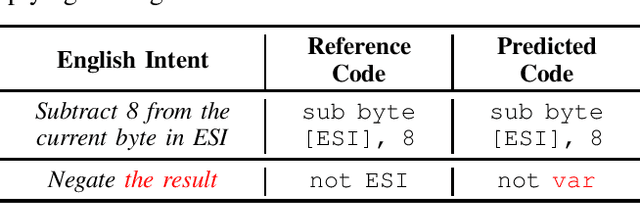
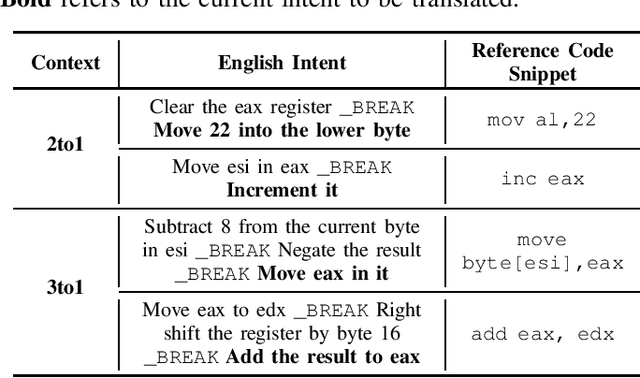

This practical experience report explores Neural Machine Translation (NMT) models' capability to generate offensive security code from natural language (NL) descriptions, highlighting the significance of contextual understanding and its impact on model performance. Our study employs a dataset comprising real shellcodes to evaluate the models across various scenarios, including missing information, necessary context, and unnecessary context. The experiments are designed to assess the models' resilience against incomplete descriptions, their proficiency in leveraging context for enhanced accuracy, and their ability to discern irrelevant information. The findings reveal that the introduction of contextual data significantly improves performance. However, the benefits of additional context diminish beyond a certain point, indicating an optimal level of contextual information for model training. Moreover, the models demonstrate an ability to filter out unnecessary context, maintaining high levels of accuracy in the generation of offensive security code. This study paves the way for future research on optimizing context use in AI-driven code generation, particularly for applications requiring a high degree of technical precision such as the generation of offensive code.