 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Based Models for Code Generation under Compilability Constraints
Paper and Code
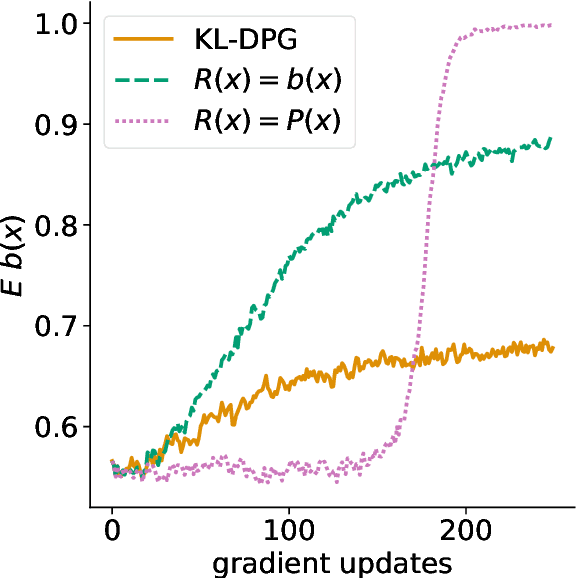
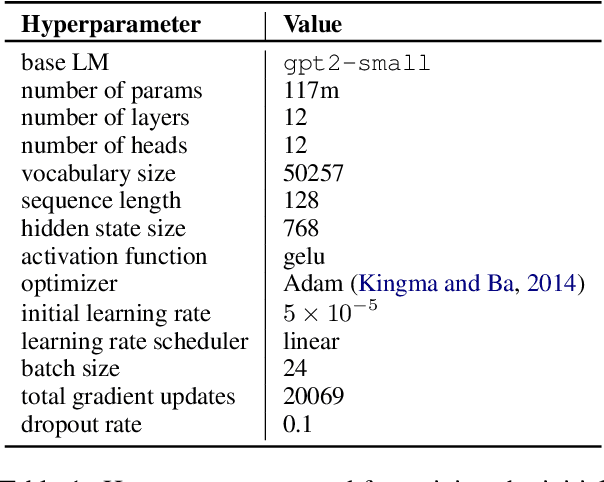
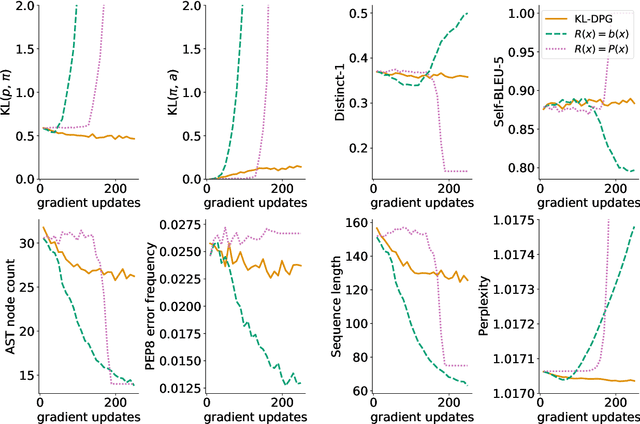

Neural language models can be successfully trained on source code, leading to applications such as code completion. However, their versatile autoregressive self-supervision objective overlooks important global sequence-level features that are present in the data such as syntactic correctness or compilability. In this work, we pose the problem of learning to generate compilable code as constraint satisfaction. We define an Energy-Based Model (EBM) representing a pre-trained generative model with an imposed constraint of generating only compilable sequences. We then use the KL-Adaptive Distributional Policy Gradient algorithm (Khalifa et al., 2021) to train a generative model approximating the EBM. We conduct experiments showing that our proposed approach is able to improve compilability rates without sacrificing diversity and complexity of the generated samples.